oracle optimizer:迁移到使用基于成本的优化器-----系列1.2
3.2基于成本的优化器(cbo)
基于成本优化器遵循计算代价的方法学。所有的执行计划随成本标识,优化器选择成本最低的一个。在执行计划中,较高的成本将意味着较高的资源。成本越低,对查询来说越高效。
cbo使用所有存储在数据字典中可用的统计资料信息和柱状图,用户提供提示和的参数设置来达成使用的成本,cbo生成所有可能访问方法的排列然后选择最合适的。排列的数量依赖于查询中出现的表数量,有时能达到约80,000个排列甚至更多,请参考系列的第二部分参数章节来设置相关参数。
cbo也可能完成诸如查询转换、视图合并或转换的操作,增加join谓词等等。
这将改变原始语句并改变正存在或者是新添加的谓词,得自新的访问计划的所有的这些目的会比原来存在的好些。注意转换并不影响返回的数据,而仅仅是执行路径,请参考系列第二部分参数章节相关联的信息。
3.2.1统计资料
统计资料按顺序提供了准确的输入以供cbo正常工作;生成的数据存储在对象中并且包括诸如表中行的数量、列中单一值、索引中页的块数等等信息。统计资料越准确,优化器提供的结果越高效。请参考本系列第三部分生成统计资料章节中怎样生成这些信息和如何最好地维持它。统计资料可能是精确的或估计的,它用compute 子句分析在对象中所有的数据,它将给优化器精确的信息以工作并且达到完美的执行计划。
用estimate子句,将会分析在对象中提及的样本大小的数据内容从而生成统计资料,样本大小会被指定成随机分析的行的数量或者行的百分比从而生成统计资料,也可以指定可选的块样例,如果系统中存在巨额表数据,它将节约时间。
好的执行计划的前提依赖于估计值和精确值有多接近,可以试验一下设置不同的样本大小来达到适合的目标或对不同类型的表产生不同的评估级别,这种思想对达到接近精确统计是相当可行的。
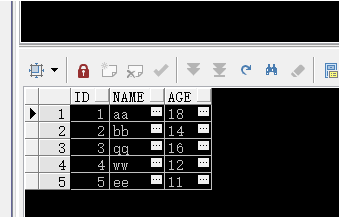
统计资料存储在所有者为sys用户的数据词典中,下面的视图显示了表、列,索引的收集统计信息.
表:
dba_tables
num_rows –行的数量
blocks – 已用的块数量
empty_blocks –未使用的空块数量
avg_space – 分配给表的平均自由空间(以字节计),考虑所有空的和自由的块.
chain_cnt – 链连或移动的行的数量
avg_row_len –以字节计的平均行的长度
last_analyzed – 上次表分析的日期
sample_size –提供给estimate统计的样本大小,对于compute则等于num_rows列的值.
global_stats –对于分区表, yes –收集统计资料将作为一个整体, no –收集统计资料将估计表
user_stats –如果用户指明为表设置统计,则为yes
对于一个表的单独分区的统计资料从dba_tab_partitions可以找到,簇统计资料从dba_clusters可以找到.
列
dba_tab_columns
num_distinct – 单一值的数量
low_value –最小值
high_value – 最高值
density – 列的聚集度.
num_nulls –涉及列空值的记录数
num_buckets – 柱状图中柱的数量,参考柱状图章节
sample_size –estimate统计提供的样本大小,如果是compute则等于全部行数
last_analyzed -上次表分析的日期
dba_tab_col_statistics 显示相似的数据,–对于分区表列统计资料从dba_part_col_statistics和dba_subpart_col_statistics可以找到
索引
dba_indexes
blevel –索引的深度,从根级到叶级
leaf_blocks –页级块的数量.
distinct keys – 单一键值的数量
avg_leaf_blocks_per_key –每一个单一键值出现的平均数量对于独特索引应该为1
avg_data_blocks_per_key –单一键值指向的表中块的平均数量
clustering_factor –决定行按索引排序的总数.如果数量靠近块的数量,则该表是按照索引顺序排序的,也就是说,页未级的的全部指向表中同一块的行.如果索引与行数接近,索引会随机排序, 也就是说, 页未级的的全部是分散指向多个块的行。
num_rows – 索引行数
sample_size - estimate统计提供的样本大小,如果是compute则等于全部行数
last_analyzed -上次表分析的日期
global_stats对于分区表, yes –收集统计资料将作为一个整体, no –收集统计资料将估计表
user_stats如果用户指明为表设置统计,则为yes
pct_direct_access –索引组织表的次要索引,有效猜测行的百分比
单一分区索引统计可从dba_ind_partitions 和dba_ind_subpartitions找到
涉及到柱状图信息的数据词典以后将会讨论. (待续)
新闻热点





疑难解答