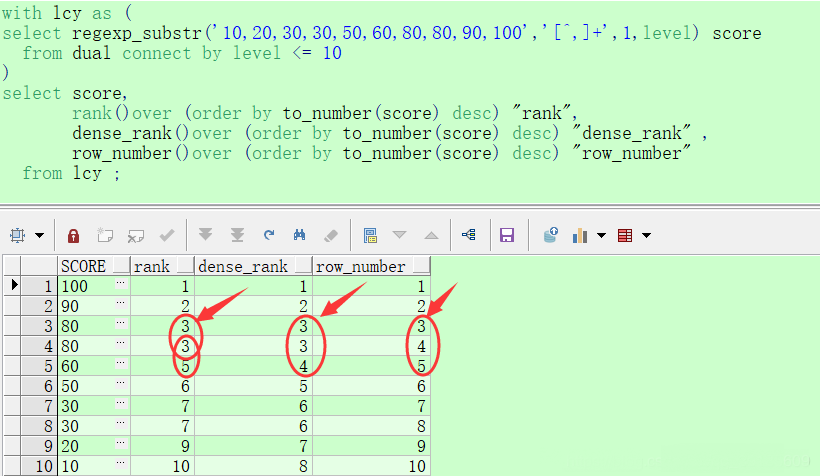
8. 使用decode函数来减少处理时间
使用decode函数可以避免重复扫描相同记录或重复连接相同的表.
例如:
select count(*),sum(sal)
from emp
where dept_no = 0020
and ename like ‘smith%’;
select count(*),sum(sal)
from emp
where dept_no = 0030
and ename like ‘smith%’;
你可以用decode函数高效地得到相同结果
select count(decode(dept_no,0020,’x’,null)) d0020_count,
count(decode(dept_no,0030,’x’,null)) d0030_count,
sum(decode(dept_no,0020,sal,null)) d0020_sal,
sum(decode(dept_no,0030,sal,null)) d0030_sal
from emp where ename like ‘smith%’;
类似的,decode函数也可以运用于group by 和order by子句中.
9. 整合简单,无关联的数据库访问
如果你有几个简单的数据库查询语句,你可以把它们整合到一个查询中(即使它们之间没有关系)
例如:
select name
from emp
where emp_no = 1234;
select name
from dpt
where dpt_no = 10 ;
select name
from cat
where cat_type = ‘rd’;
上面的3个查询可以被合并成一个:
select e.name , d.name , c.name
from cat c , dpt d , emp e,dual x
where nvl(‘x’,x.dummy) = nvl(‘x’,e.rowid(+))
and nvl(‘x’,x.dummy) = nvl(‘x’,d.rowid(+))
and nvl(‘x’,x.dummy) = nvl(‘x’,c.rowid(+))
and e.emp_no(+) = 1234
and d.dept_no(+) = 10
and c.cat_type(+) = ‘rd’;
(译者按: 虽然采取这种方法,效率得到提高,但是程序的可读性大大降低,所以读者 还是要权衡之间的利弊)
10. 删除重复记录
最高效的删除重复记录方法 ( 因为使用了rowid)
delete from emp e
where e.rowid > (select min(x.rowid)
from emp x
where x.emp_no = e.emp_no);
11. 用truncate替代delete
当删除表中的记录时,在通常情况下, 回滚段(rollback segments ) 用来存放可以被恢复的信息. 如果你没有commit事务,oracle会将数据恢复到删除之前的状态(准确地说是
恢复到执行删除命令之前的状况)
而当运用truncate时, 回滚段不再存放任何可被恢复的信息.当命令运行后,数据不能被恢复.因此很少的资源被调用,执行时间也会很短.
(译者按: truncate只在删除全表适用,truncate是ddl不是dml)
12. 尽量多使用commit
只要有可能,在程序中尽量多使用commit, 这样程序的性能得到提高,需求也会因为commit所释放的资源而减少:
commit所释放的资源:
a. 回滚段上用于恢复数据的信息.
b. 被程序语句获得的锁
c. redo log buffer 中的空间
d. oracle为管理上述3种资源中的内部花费
(译者按: 在使用commit时必须要注意到事务的完整性,现实中效率和事务完整性往往是鱼和熊掌不可得兼)