英伟达总监亲测FSD v14:已经通过了物理图灵测试
2026-01-01 17:06:50
供稿:网友
所谓端到端,即「光子进,控制出」(Photons In,Controls Out)。
摄像头捕捉的原始视频流直接输入到巨大的神经网络中,网络经过层层计算,直接输出方向盘转角和油门刹车指令。
中间不再有人类编写的「红灯」概念,系统只是通过观察数百万小时的人类驾驶视频,学习到了「看到红八角形物体时减速」这一像素级特征与车辆运动之间的概率关联。
这一转变的意义在于,系统不再是在「执行规则」,而是在「模仿直觉」。
人类驾驶员在过弯时并不是在脑中计算曲率半径公式,而是凭感觉打方向。
FSD v14正是模拟了这种基于经验的直觉过程。
FSD v14不仅仅是v12的优化版,更引入了多模态大模型的特性,极有可能采用了视觉-语言-动作架构。
根据泄露的技术细节,FSD v14的神经网络不仅输出控制信号,还输出语言和3D空间重建。
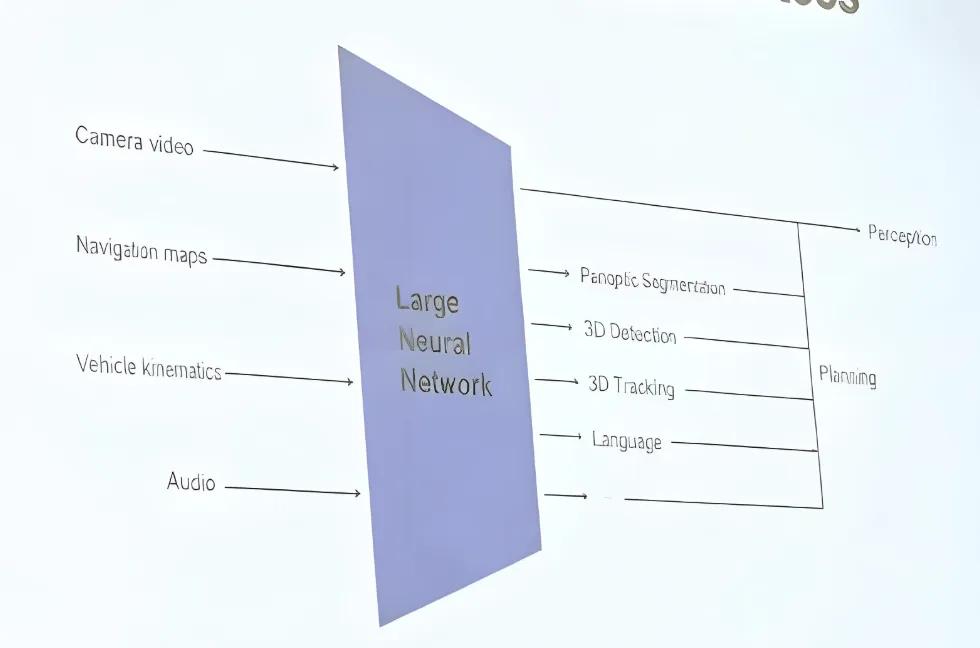
从ICCV流出的幻灯片可以看到,特斯拉的FSD核心网络输入包括七路高分辨率摄像头视频、车辆自身运动信息、导航与音频信号。
输出则包含语义分割、占用网格、3D高斯特征、语言表达以及最终的控制动作,FSD或已接入视觉-语言-动作(VLA)框架,使模型具备「解释」与「思考」的能力。
这意味着系统在内部进行着某种形式的「思维链」推理。
例如,在遇到一个复杂的施工路段时,传统的感知系统可能只能识别出一堆障碍物;而VLA架构的FSD可能会在内部推理:
「我看到了‘道路封闭’的标志,但左侧有一位工人正在挥舞旗帜,结合导航信息,我应该无视标志,跟随工人的指引向左绕行。」
语言能力的引入,解决了端到端模型最大的痛点:「黑盒」问题。
通过让模型输出自然语言解释,工程师可以回溯系统的决策逻辑,这被称为「可解释的中间层」。
这种能力使得FSD v14不仅能「做」,还能「说」(尽管目前主要用于开发调试),使其具备了初步的逻辑验证能力。
早期的FSD版本常被诟病为只有「金鱼记忆」,即只关注当前帧的画面。
FSD v14通过引入长短时记忆机制和3D占用网络,获得了类似人类的「物体恒常性」认知。
如果一个孩子跑进了一辆停在路边的货车后面,即使摄像头此刻看不到孩子,v14的「世界模型」中依然保留着孩子的3D体素(Voxel),并预测其可能出现的位置。
这种时空推理能力是其能够通过物理图灵测试的关键:它不仅在看,更在理解和预测物理世界的演变。
当然要训练端到端的庞大模型,离不开芯片的支持。
Tesla的自动驾驶硬件进化史,是一部从依赖外部供应商到全面自研的独立史。
Hardware 1.0(Mobileye时代):2014-2016年,Tesla依赖Mobileye的Eye Q3芯片。这是一套基于规则的视觉系统,直到2016年因一场致死事故及对数据共享的分歧,双方决裂。
Hardware 2.0/2.5(NVIDIA时代):2016-2019年,Tesla转向NVIDIA,采用了DrivePX2计算平台。
这是一台算力达到12TOPS的「后备箱超算」,支持了Tesla早期的视觉算法。
然而,马斯克意识到,通用的GPU架构对于车载推理来说,功耗过高且成本昂贵。(这里很像谷歌自己研发了TPU)
Hardware 3.0(FSD Chip时代):2019年,Tesla发布了由传奇芯片架构师Jim Keller(曾任职AMD、Intel)领导设计的自研FSD芯片。
这是一个专用集成电路(ASIC),专门为神经网络的矩阵乘法优化,算力激增至144TOPS,而功耗和成本大幅降低。这一刻,Tesla在车载推理端彻底摆脱了对NVIDIA的依赖。
关于这位大佬Jim Keller的介绍,可以查看之前这篇:英伟达亲手终结CUDA「护城河」?传奇芯片架构师引发争议
尽管在车端分道扬镳,但在云端训练,Tesla却是英伟达最贪婪的客户之一。
FSD v14那种「端到端」的庞大神经网络,需要吞噬数以亿计的视频片段进行训练,这需要极其恐怖的算力支持。
Tesla建立了巨大的超级计算机集群(如DojoCortex),其中部署了数万张NVIDIA H100和H200 GPU。
这就形成了一种独特的「竞合」关系:
Tesla使用自研的HW3/HW4芯片,甚至未来的AI5芯片,通过垂直整合将成本压到极致。
Tesla依然依赖NVIDIA的CUDA生态和最强算力来「教育」它的AI。
黄仁勋对此表现出了极高的战略格局。
他多次公开称赞Tesla在自动驾驶领域的领先地位,承认Tesla是目前唯一能有效利用其最强算力的车企,并表示「每一个车企未来都必须拥有自动驾驶能力」。