原作者:Bert Scalzo
目前,HP,Compaq,Dell,IBM 以及 Oracle 都在加快速度拥抱 Linux ,这个开放源码的操作系统。根据 eWeek 的统计,去年 Linux 服务器的销售量大约占据了 Compaq 的 30%,Dell 的 13.7%,IBM 的 13.5%。而且 IBM 2001年度在 Linux 上的投入有 10 个亿。 Intel 最新的 64 位的 Itanium CPU 只支持四种操作系统:Windows, Linux, AIX 和 HP-UX。我们也不要忘记 Oracle 的 9i 数据库 Linux 版本要比 Windows 版本早一个月。
尽管 Linux 能跑在从 IBM S/390 到 Sun SPARC 结构的服务器,但是对于大多数人来说,Intel 还是 Linux 跑得最多的平台。本文就是要讲述通过简单的性能调正,使 Oracle 的性能提升 1000% 的办法。
本文采用的测试环境是一台 Compaq 4 CPU,512 MB ,8 部 7200 rpm SCSI 磁盘的服务器,然后在几乎同样的单 CPU Athlon 系统上作了测试,内存一样,但是只有一部 7200 rpm 的 Ultra 100 IDE 磁盘。尽管最后的结果和得到的百分比不一样,但是观测得到的性能提升是一致的。
为了简单起见,我们的测试环境采用 TPC 基准测试,它广泛地用于 OLTP 的负荷测试。Quest 公司有一个叫做 Benchmark Factory 的工具,使测试工作变得就像发送电子邮件一样简单。
下面我们将分别通过 DB 的调整和 OS 的调整来看测试的结果。
DB1 的初始化参数一般不常见,为了说明问题,我们使用这些参数并作为基准。
DB1: Initial Database
Database Block Size 2K
SGA Buffer Cache 64M
SGA Shared Pool 64M
SGA Redo Cache 4M
Redo Log Files 4M
Tablespaces Dictionary
TPC Results Load Time (Seconds) 49.41
Transactions / Second 8.152
显然需要加大 SGA 大小,我们来看 DB2 的结果:
DB2: Cache & Pool
Database Block Size 2K
SGA Buffer Cache 128M
SGA Shared Pool 128M
SGA Redo Cache 4M
Redo Log Files 4M
Tablespaces Dictionary
TPC Results Load Time (Seconds) 48.57
Transactions / Second 9.147
增大 SGA 已经缓冲看来对于性能的提升并不显著,加载时间只提升了 1.73%。下面我们增加 SGA 重做日志的大小:
DB3: Log Buffer
Database Block Size 2K
SGA Buffer Cache 128M
SGA Shared Pool 128M
SGA Redo Cache 16M
Redo Log Files 16M
Tablespaces Dictionary
TPC Results Load Time (Seconds) 41.39
Transactions / Second 10.088 我们可以看到加载时间提升了 17.35%,TPS 也提升了 9.33%。因为加载和同时插入,更新,删除需要比 8M 大的空间,但是看起来增加内存性能并没有显著提升,我们加大块大小:
DB4: 4K Block
Database Block Size 4K
SGA Buffer Cache 128M
SGA Shared Pool 128M
SGA Redo Cache 16M
Redo Log Files 16M
Tablespaces Dictionary
TPC Results Load Time (Seconds) 17.35
Transactions / Second 10.179
我们看到加载时间提升了 138%!而对 TPS 值没有很大的影响。下面一个简单的念头是表空间的管理从目录切换为本地:
DB5: Local Tablespaces
Database Block Size 4K
SGA Buffer Cache 128M
SGA Shared Pool 128M
SGA Redo Cache 16M
Redo Log Files 16M
Tablespaces Local
TPC Results Load Time (Seconds) 15.07
Transactions / Second 10.425
下面我们把数据库块加大到 8K 来看结果:
DB6: 8K Block
Database Block Size 8K
SGA Buffer Cache 128M
SGA Shared Pool 128M
SGA Redo Cache 16M
Redo Log Files 16M
Tablespaces Local
TPC Results Load Time (Seconds) 11.42
Transactions / Second 10.683
看来结果并不坏,我们没有理由继续增加块大小了,我们还没有根据 CPU 个数调整相应的参数,这次我们设置 I/O 的进程数来继续调整:
DB7: I/O Slaves
Database Block Size 8K
SGA Buffer Cache 128M
SGA Shared Pool 128M
SGA Redo Cache 16M
Redo Log Files 16M
Tablespaces Local
dbwr_io_slaves 4
lgwr_io_slaves (derived) 4
TPC Results
Load Time (Seconds) 10.48
Transactions / Second 10.717
我们的测试是基于 Red Hat 6.2 进行的,内核版本为 2.2.14-5smp。对于 Linux 的内核而言,有将近几百个参数可以调整,包括对 CPU 类型,SMP 支持,APIC 支持,DMA 支持,IDE DMA 缺省参数的使用以磁盘限额支持。根据 Oracle 的文档,我们要做的主要调整是共享内存和信号量的大小,SHMMAX 最少配置 0x13000000,SEMMNI, SEMMSL 和 SEMOPN 分别至少设置 100, 512, 100。这些参数的设置可以通过下面的命令实现:
# echo 0x13000000 >/proc/sys/kernel/shmmax
# echo 512 32000 100 100 >/proc/sys/kernel/sem
OS1: 单内核和 IPC
TPC Results
Load Time (Seconds) 9.54
Transactions / Second 11.511
我们有理由相信采用新的内核版本(2.2.16-3smp)也应该有性能的提升:
OS2: Newer minor version kernel TPC Results
Load Time (Seconds) 9.40
Transactions / Second 11.522
目前已经有 2.4 版本的内核,和 2.2 相比,性能上有了很大的提升,我们采用 2.4.1smp:
OS3: Newer major version kernel TPC Results
Load Time (Seconds) 8.32
Transactions / Second 12.815
Linux 缺省读操作时更新最后一次读的时间,但是这个对我们来说并不重要,因此我们关闭这个选项,通过设置 noatime 的文件属性来实现。(对于 Win NT 和 2000 有相似的设置)
如果只是相对 Oracle 的数据文件设置,我们的命令是
chattr +A file_name
对整个目录的实施办法:chattr -R +A directory_name
最好的办法是修改 /etc/fstab ,针对每个文件系统入口,添加 noatime 关键字。
OS4: noatime file attribute
TPC Results
Load Time (Seconds) 5.58
Transactions / Second 13.884
另外一个调整 Linux I/O 的办法是虚拟内存子系统的调整,修改 /ect/sysctl.cong 文件,增加下面一行:
vm.bdflush = 100 1200 128 512 15 5000 500 1884 2
根据 /usr/src/Linux/Documentation/sysctl/vm.txt 的说法:
第一个参数100 %:控制缓冲区中最大的脏缓冲数据,增加这个值意味着 Linux 可以延迟磁盘写。
第二个参数 1200 ndirty:给出 bdflush 一次能够写入磁盘的最大脏缓冲。
第三个参数 128 nrefill:当调用 refill_freelist() 时,bdflush 添加到自由缓冲区中的最大缓冲数目。
refill_freelist() 512:当这个数目超过 nref_dirt 脏缓冲时,将唤醒 bdflush。
第五个 15 和最后两个参数 1884 和 2,系统未使用,我们不做修改。
age_buffer 50*HZ, age_super 参数 5*HZ:控制 Linux 把脏缓冲写到磁盘的最多等待时间。数值用时钟滴答数(jiffies)表示,每秒为 100 个 jiffies 。
OS5: bdflush settings TPC Results
Load Time (Seconds) 4.43
Transactions / Second 14.988
经过以上一系列调整后,我们得到的最终加载时间减少了 1015.35%,TPS 增加
浅谈Oracle 性能优化
基于大型Oracle数据库应用开发已有6个年头了,经历了从最初零数据演变到目前上亿级的数据存储。在这个经历中,遇到各种各样的性能问题及各种性能优化。
在这里主要给大家分享一下数据库性能优化的一些方法和见解。
1、服务器要求及配置
服务器处理器性能很关键,CPU的主频要高,要有较大的内存,IO读写速度块。
如何验证一台服务器的IO读写效率如何了,可以通过IOPS这个指标来衡量。普及一下IOPS的定义:IOPS (Input/Output Operations Per Second),即每秒进行读写(I/O)操作的次数,多用于数据库等场合,衡量随机访问的性能。目前SSD硬盘的IOPS基本是万级别。但相对的成本也是比较高的。
在Oracle数据使用场景中,可以实现如下语句来查看当前服务器的IOPS:
declare max_iops_out pls_integer ; max_mbps_out pls_integer ; actual_latency_out pls_integer ; begin dbms_resource_manager.calibrate_io( max_iops=>max_iops_out, max_mbps=>max_mbps_out, actual_latency=>actual_latency_out); dbms_output.put_line('max_iops = ' || max_iops_out || ',max_mbps = ' || max_mbps_out || ',actual_latency = ' || actual_latency_out); end; 2、Oracle系统级的优化
这里主要是针对ORACLE核心的优化,包括Oracle内存设置、文件大小、日志文件大小、回滚日志及各种系统级参数的设定。
那么如何发现目前的设置是否合理了,
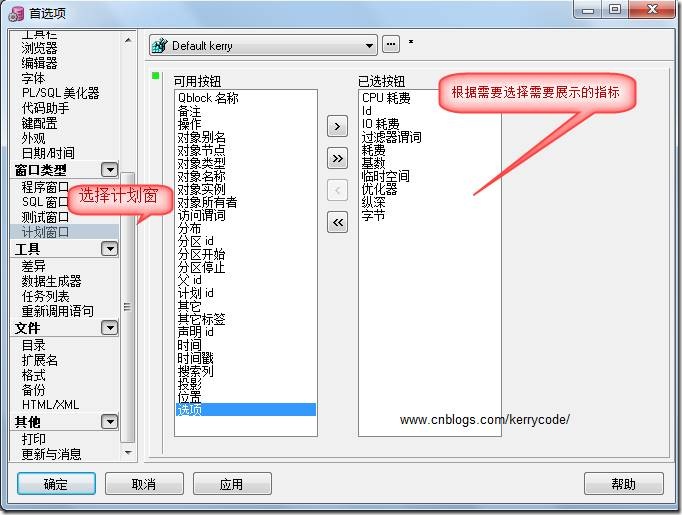
A、在Oracle中提供一个性能分析报告AWR和ASH报告.可以通过命令来获取该份报告。里面涉及到各种指标值:内存设定是否合理、影响ORACLE慢的几大因素,数据文件读写速度等。
B、也可以通过ORALCE-EM中的性能模块,来检测每个时间节点ORALCE的运行情况,从中捕获那些耗资源的SQL语句,从而进行优化。
3、Oracle SQL语句的优化
数据库在百万级别,遇到的任何性能问题时,均可以通过SQL语句的优化。优化的层面有2种:
1、通过索引,这种优化的速度最快,而且见效也很明显。索引的合理使用我就不在这里叙述,网上很多。
2、通过更改SQL语句的查询逻辑和算法。有一个比较很效的原则是:先过滤小的结果集,然后通过这个小的结果集和其他表做关联。
在这里希望大家可以提提一些其他观点或不同看法。
新闻热点





疑难解答