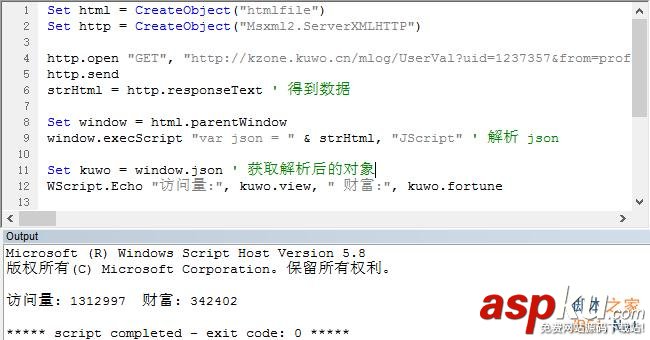
本文主要实现了使用vbs脚本调用wget,下载网站所有页面到本脚本目录,并扫描本脚本目录中所有文件,读取本脚本目录中的所有网页,匹配图片 URL 地址,保存所有图片 URL 地址到 url-img.txt 文件,然后调用wget: 下载 url-img.txt 指定的图片到本脚本 img 目录
vbs 函数过程:
1. 调用wget: 下载网站所有页面到本脚本目录 ……
2. 扫描本脚本目录中所有文件 ……
3. 读取本脚本目录中的所有网页,匹配图片 URL 地址 ……
4. 保存所有图片 URL 地址到 url-img.txt 文件 ……
5. 调用wget: 下载 url-img.txt 指定的图片到本脚本 img 目录 ……
- ' wget_img.vbs
- Call Main()
- Sub Main()
- ' CMD 模式
- If Not (LCase(Right(WScript.FullName,11)) = LCase("CScript.exe")) Then
- CreateObject("WScript.Shell").Run "cscript.exe //nologo """ & WScript.ScriptFullName & """", 1, False
- WScript.Quit(1)
- End If
- Dim wso, strMeDir
- Set wso = WScript.CreateObject("WScript.Shell")
- strMeDir = Left(WScript.ScriptFullName, InStrRev(WScript.ScriptFullName,"/")-1)
- ' 启动 wget下载网站所有页面到本脚本目录的 720.hao2046.net 文件夹
- WScript.Echo "1. 启动 wget下载网站所有页面到本脚本目录的 720.hao2046.net 文件夹 ……"
- wso.Run "wget -r -p -k -c -x -A=jpg,htm,html 720.hao2046.net -P """ & strMeDir & """", 1, True
- ' 扫描 720.hao2046.net 文件夹中所有文件
- WScript.Echo "2. 扫描 720.hao2046.net 文件夹中所有文件 ……"
- Dim strFolderspec, strHTML, strURL
- Dim arr() : ReDim Preserve arr(0)
- strFolderspec = strMeDir & "/720.hao2046.net"
- Call ScanFolder(arr, strFolderspec)
- ' 建立正则表达式。
- Dim regEx
- Set regEx = CreateObject("VBScript.RegExp") ' 建立正则表达式。
- regEx.IgnoreCase = True ' 设置是否区分大小写。
- regEx.Global = True ' 设置全局替换。
- regEx.MultiLine = True ' 设置多行匹配模式
- ' 查找所有文件
- WScript.Echo "3. 读取 720.hao2046.net 文件夹中的所有网页,匹配图片 URL 地址 ……"
- For i = 0 To UBound(arr)
- If LCase(Right(arr(i),5)) = ".html" Or LCase(Right(arr(i),4)) = ".htm" Then
- ' 读取文件,匹配图片 URL 地址
- strHTML = ReadPfile(arr(i), "gb2312")
- regEx.Pattern = "src=['""]http:///S+/.jpg['""]"
- Set Matches = regEx.Execute(strHTML) ' 执行搜索。
- For Each Match in Matches ' 遍历匹配集合。
- If Not Match.Value = "" Then
- regEx.Pattern = "(src=['""])*(['""])*"
- strURL = strURL & regEx.Replace(Match.Value, "") & vbCrLf
- End If
- Next
- End If
- Next
- ' 保存所有图片 URL 地址
- WScript.Echo "4. 保存所有图片 URL 地址到 url-img.txt 文件 ……"
- Call SavePfile(strMeDir & "/url-img.txt", "utf-8", strURL)
- ' 启动 wget 下载图片到本脚本 img 目录
- WScript.Echo "5. 启动 wget 下载 url-img.txt 指定的图片到本脚本 img 目录 ……"
- wso.Run "wget -c -x -t 5 -i """ & strMeDir & "/url-img.txt"" -P """ & strMeDir & "/img""", 1, True
- Msgbox "完成!"
- End Sub
- '===========================================================================================
- '按编码读取txt文件内容
- Function ReadPfile(ByVal FileName, ByVal FileCode)
- Dim objStream
- Set objStream = CreateObject("ADODB.Stream")
- '
- With objStream
- .Type = 2
- .Mode = 3
- .open
- .Charset = FileCode '不同编码时自己换,Chinese (Simplified) (GB2312),中文 GBK ,繁体中文 Big5 ,日文 EUC-JP ,韩文 EUC-KR,charset=UTF-8(国际化编码),ANSI,Unicode,unicode big endian
- .LoadFromFile FileName
- ReadPfile = .ReadText
- .Close
- End With
- Set objStream = Nothing
- End Function
- '===========================================================================================
- '保存文件为unicode格式文本
- Function SavePfile(ByVal FileName, ByVal FileCode, ByVal TextString)
- Dim objStream
- Set objStream = CreateObject("ADODB.Stream")
- With objStream
- .Type = 2
- .Mode = 3
- .Charset = FileCode '不同编码时自己换,Chinese (Simplified) (GB2312),中文 GBK ,繁体中文 Big5 ,日文 EUC-JP ,韩文 EUC-KR,charset=UTF-8(国际化编码),ANSI,Unicode,unicode big endian
- .open
- .WriteText TextString
- .SaveToFile FileName, 2
- .Close
- End With
- Set objStream = Nothing
- End Function
- ' Dim arr() : ReDim Preserve arr(0)
- ' Call ScanFolder(arr, "V:/")
- Sub ScanFolder(ByRef arr, ByVal strFolderspec)
- On Error Resume Next
- Dim fso, objFolder
- Set fso = Createobject("Scripting.FileSystemObject")
- Set objFolder = fso.getfolder(strFolderspec)
- ReDim Preserve arr(UBound(arr)+1)
- arr(UBound(arr)) = strFolderspec & "/"
- For Each subFile In objFolder.files
- ReDim Preserve arr(UBound(arr)+1)
- arr(UBound(arr)) = subFile.path
- Next
- For Each subFolder In objFolder.subfolders
- ScanFolder arr, subFolder.path
- Next
- Set fso = NoThing
- Set objFolder = NoThing
- End Sub
附网页文件查找字符串代码(findstr_html.vbs):
- ' findstr_html.vbs
- Call Main()
- Sub Main()
- ' CMD 模式
- If Not (LCase(Right(WScript.FullName,11)) = LCase("CScript.exe")) Then
- CreateObject("WScript.Shell").Run "cscript.exe //nologo """ & WScript.ScriptFullName & """", 1, False
- WScript.Quit(1)
- End If
- Dim strMeDir
- strMeDir = Left(WScript.ScriptFullName, InStrRev(WScript.ScriptFullName,"/")-1)
- Dim regEx, strHTML, strURL
- ' 扫描文件夹
- Dim arr() : ReDim Preserve arr(0)
- Call ScanFolder(arr, strMeDir & "/720.hao2046.net")
- If UBound(arr) = 0 Then
- WScript.Echo strMeDir & "/720.hao2046.net" & ", Not Found!"
- Exit Sub
- End If
- ' 建立正则表达式。
- Set regEx = CreateObject("VBScript.RegExp") ' 建立正则表达式。
- regEx.IgnoreCase = True ' 设置是否区分大小写。
- regEx.Global = True ' 设置全局替换。
- regEx.MultiLine = True ' 设置多行匹配模式
- Do
- strPattern = InputBox("请输入要匹配的正则表达式:","查找所有网页文件","123456")
- strInfo = strPattern & vbCrLf & "Not Found!"
- For i = 0 To UBound(arr)
- If LCase(Right(arr(i),5)) = ".html" Or LCase(Right(arr(i),4)) = ".htm" Then
- 'WScript.Echo arr(i)
- strHTML = ReadPfile(arr(i), "gb2312")
- If InStr(strHTML, strPattern)>0 Then
- strInfo = strPattern & vbCrLf & arr(i) & vbCrLf
- Exit For
- Else
- 'regEx.Pattern = "src=['""]http:///S+/.jpg['""]"
- regEx.Pattern = strPattern
- Set Matches = regEx.Execute(strHTML) ' 执行搜索。
- For Each Match in Matches ' 遍历匹配集合。
- If Not Match.Value = "" Then
- 'regEx.Pattern = "(src=['""])*(['""])*"
- 'strURL = strURL & regEx.Replace(Match.Value, "") & vbCrLf
- strInfo = strPattern & vbCrLf & arr(i) & vbCrLf
- Exit For
- End If
- Next
- End If
- End If
- Next
- WScript.Echo strInfo
- Loop
- End Sub
- '===========================================================================================
- '按编码读取txt文件内容
- Function ReadPfile(ByVal FileName, ByVal FileCode)
- Dim objStream
- Set objStream = CreateObject("ADODB.Stream")
- '
- With objStream
- .Type = 2
- .Mode = 3
- .open
- .Charset = FileCode '不同编码时自己换,Chinese (Simplified) (GB2312),中文 GBK ,繁体中文 Big5 ,日文 EUC-JP ,韩文 EUC-KR,charset=UTF-8(国际化编码),ANSI,Unicode,unicode big endian
- .LoadFromFile FileName
- ReadPfile = .ReadText
- .Close
- End With
- Set objStream = Nothing
- End Function
- ' Dim arr() : ReDim Preserve arr(0)
- ' Call ScanFolder(arr, "V:/")
- Sub ScanFolder(ByRef arr, ByVal strFolderspec)
- On Error Resume Next
- Dim fso, objFolder
- Set fso = Createobject("Scripting.FileSystemObject")
- Set objFolder = fso.getfolder(strFolderspec)
- ReDim Preserve arr(UBound(arr)+1)
- arr(UBound(arr)) = strFolderspec & "/"
- For Each subFile In objFolder.files
- ReDim Preserve arr(UBound(arr)+1)
- arr(UBound(arr)) = subFile.path
- Next
- For Each subFolder In objFolder.subfolders
- ScanFolder arr, subFolder.path
- Next
- Set fso = NoThing
- Set objFolder = NoThing
- End Sub
提示:
1. 警告:请不要直接运行代码,这里的示范网址可能无法访问、或缺乏安全性,请改为其他网址再使用。
2. 请将 wget.exe 放置于脚本同一目录下,然后执行。文件结构如下:
../wget.exe
../wget_img.vbs
../findstr_html.vbs
新闻热点





疑难解答