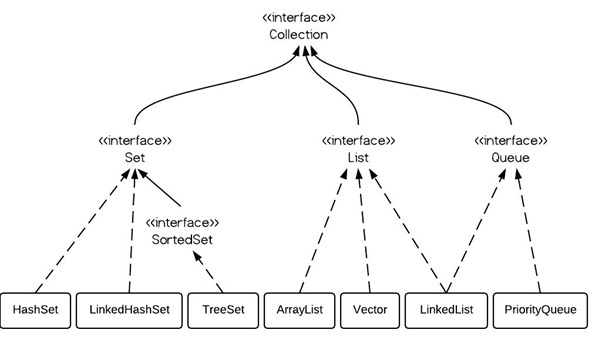
Set集合,它类似于一个罐子,程序可以依次把多个对象放进Set集合,而Set集合通常不能记住元素的添加顺序。Set集合与Collection提供的方法基本相同,它定义的方法如下:

Set集合不允许包含相同的元素,如果试图把两个相同的元素加入同一个Set集合中,则添加操作失败,add()方法返回false,且新元素并不会被加入。
HashSet是Set接口的典型实现,大多数的时候使用Set集合时就是使用这个实现类。HashSet按Hash算法来存储集合元素,因此具有很好的存取和查找性能。 HashSet具有以下特点:
HashSet不是同步的,如果多个线程同时访问一个HashSet,假设两个或两个以上线程同时修改了HashSet集合时,则必须通过代码来保证其同步。否则很可能会出现异常。3.集合元素可以是null当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据该hashCode值决定该对象在HashSet中的存储位置。
如果有两个元素通过equals()方法比较返回true,但它们的hashCode()方法返回值不相等,HashSet将会把它们存储在不同的位置,依然可以添加成功。
也就是说,HashSet集合判断两个元素相等的标准是两个对象的hashCode()方法返回值相等,并且两个对象通过equals()方法比较也相等
下面举一个例子:
import java.util.HashSet;class A { /** * Class A 的equals()方法总是返回true,但是没有重写其hashCode()方法 */ @Override public boolean equals(Object obj) { return true; }}class B { /** * Class B 的hashCode()方法总是返回1,但是没有重写其equals()方法 */ @Override public int hashCode() { return 1; }}class C { /** * Class C 的hashCode()方法总是返回2,且重写其equals()方法总是返回true */ @Override public int hashCode() { return 2; } @Override public boolean equals(Object obj) { return true; }}public class HashSetTest { public static void main(String[] args) { HashSet sets = new HashSet(); sets.add(new A()); sets.add(new A()); sets.add(new B()); sets.add(new B()); sets.add(new C()); sets.add(new C()); System.out.PRintln(sets); }}上面的程序定义了A、B、C三个类,它们分别重写了equals()、hashCode()两个方法的一个或全部。并且在主方法中,向sets集合中添加了两个A对象,两个B对象和两个C对象,其中C类重写了equals()方法总是返回true,hashCode()方法总是返回2,这将导致HashSet把两个C对象当成同一个对象,运行上面的程序,可以看到如下结果:
可以看到,即使两个A对象通过equals()方法比较返回true,但HashSet仍然把它们当成两个对象;即使两个B对象的hashCode()方法返回值相同,都是1,但HashSet也把它们当成两个对象。
从上面的例子,我们可以得到这样的结论:
当把一个自定义对象放入HashSet中时,如果需要重写该对象对应类的equals()方法,则也应该重写其hashCode()方法。规则是:如果两个对象通过equals()方法比较返回true,这两个对象的hashCode值也应该相同。
如果两个对象通过equals()方法比较返回true,但这两个对象的hashCode()方法返回不同的hashCode值时,这将导致HashSet会把这两个对象保存在Hash表的不同位置,从而使两个对象都可以添加成功,这就与Set集合的规则冲突了。
如果两个对象的hashCode()方法返回的hashCode值相同,但它们通过equals()方法比较返回false时,这种情况更为麻烦:因为两个对象的hashCode值相同,HashSet将试图把它们保存在同一个位置,但又不行(否则将会只剩下一个对象),所以实际上,会在这个位置上用链式结构来保存多个对象;而HashSet访问集合元素时也是根据元素的hashCode值来快速定位的,如果HashSet中两个以上的元素具有相同的hashCode值,这将会导致性能下降。
HashSet中每个能存储元素的“槽位”(slot)通常称为“桶”(bucket),如果有多个元素的hashCode值相同,但它们通过equals()方法比较返回false,就需要在一个“桶”里放多个元素,这样会导致性能的降低。
总结一下:
在集合中,判断两个对象是否相等的规则是: (1)第一步,判断hashCode()是否相等,如果hashCode()相等,则查看第二步,否则不相等。 (2)第二步,判断equals()是否相等,如果相等,则两obj相等,否则还是不相等。
所以: (1)两个obj,如果equals()相等,则hashCode()一定相等。(否则Set集合就乱套了) (2)两个obj,如果hashCode()相等,equals()不一定相等。(Hash散列值有冲突的情况,虽然概率很低)
通过前面的介绍,我们可以看到hashCode()方法对于HashSet集合的重要性。那么如果我们要重写一个类的hashCode()方法,我们该怎么着手呢?
重写hashCode()方法有三个基本原则:
1.在程序运行过程中,同一个对象多次调用hashCode()方法应该返回相同的值 2.当两个对象通过equals()方法比较返回true时,这两个对象的hashCode()方法应该返回相等的值。 3.对象中用作equals()方法比较标准的实例变量,都应该用于计算hashCode值。
重写hashCode()的一般步骤如下:
1.把对象内每个有意义的实例变量(即每个参与equals()方法比较标准的实例变量)计算出一个int类型的hashCode值。 计算方式如下(假设实例变量为f):
| 实例变量类型 | 计算方式 |
|---|---|
boolean | hashCode = (f ? 0 : 1); |
整数类型(byte,short,char,int) | hashCode = (int)f; |
long | hashCode = (int)(f^(f>>>32)); |
float | hashCode = Float.floatToIntBits(f); |
double | long L = Double.doubleToLongBits(f); hashCode = (int)(L ^ (L >>> 32)); |
| 引用类型 | hashCode = f.hashCode() |
2.用第1步计算出来的多个hashCode值组合计算出一个hashCode值返回。 比如如下,直接进行简单的相加:
return f1.hashCode() + (int)(f2 ^ (f2 >>> 32));当然,为了避免直接相加产生偶然的相等,可以通过为各实例变量的hashCode值乘以任意一个质数后再相加。如下:
return f1.hashCode() * 17 + (int)(f2 ^ (f2 >>> 32)) * 31;一定要注意的是:当程序把可变对象添加到HashSet中之后,尽量不要去修改该集合元素中参与计算hashCode()和equals()方法的实例变量,否则可能会导致HashSet无法正确操作这些集合元素!
HashSet有一个子类是LinkedHashSet,它的用法与HashSet基本一致,LinkedHashSet集合也是根据元素的hashCode值来决定元素的存储位置,但它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序来保存的。也就是说,当遍历LinkedHashSet集合里的元素时,将会按照元素的添加顺序来访问集合里的元素。
LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet的性能,但在迭代访问Set`里的全部元素时将有很好的性能,因为它以链表来维护内部顺序。
TreeSet是SortedSet接口的实现类,正如SortedSet名字所暗示的,TreeSet可以确保集合元素处于排序状态。它使用红黑树算法来维护集合元素的次序。
与HashSet集合相比,TreeSet还提供了如下几个额外的方法:
| 方法 | 说明 |
|---|---|
Comparator comparator() | 如果TreeSet采用了定制排序,则该方法返回定制排序所使用的Comparator;如果TreeSet采用了自然排序,则返回null |
Object first() | 返回集合中的第一个元素 |
Object last() | 返回集合中最后一个元素 |
Object lower(Object e) | 返回集合中位于指定元素之前的元素(即小于指定元素的最大元素,参考元素不需要是TreeSet集合里的元素) |
Object higher(Object e) | 返回集合中位于指定元素之后的元素(即大于指定元素的最大元素,参考元素不需要是TreeSet集合里的元素) |
SortedSet subSet(Object fromElement, Object toElement) | 返回此Set的子集合,范围从fromElement(包含)到toElement(不包含) |
SortedSet headSet(Object toElement) | 返回此Set的子集,由小于toElement的元素组成 |
SortedSet tailSet(Object fromElement) | 返回此Set的子集,由大于fromElement的元素组成 |
下面是一个测试程序:
public static void main(String[] args) { TreeSet nums = new TreeSet<>(); nums.add(5); nums.add(2); nums.add(10); nums.add(-9); // 输出集合元素,可以看到集合已经排好了序,[-9, 2, 5, 10] System.out.println(nums); // 输出集合的第一个元素,-9 System.out.println(nums.first()); // 输出集合的最后一个元素,10 System.out.println(nums.last()); // 返回小于5的子集,不包含5,[-9, 2] System.out.println(nums.headSet(5)); // 返回大于等于5的子集,[5, 10] System.out.println(nums.tailSet(5)); // 返回大于等于-3,小于4的子集,[2] System.out.println(nums.subSet(-3, 4));}与HashSet集合采用hash算法来决定元素的存储位置不同,TreeSet采用红黑树的数据结构来存储集合元素。它支持两种排序方法:自然排序和定制排序。在默认情况下,TreeSet采用自然排序。
TreeSet会调用集合元素的compareTo(Object obj)方法来比较元素之间的大小关系,然后将集合按照升序排列,这就是自然排序。
(1)Java提供了一个Comparable接口,该接口定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现该接口的类必须实现该方法,实现了该接口的类的对象就可以比较大小。 (2)当一个对象调用该方法与另一个对象进行比较时,例如obj1.compareTo(obj2),如果该方法返回0,则表明这两个对象是相等的;如果该方法返回一个正整数,则表明obj1大于obj2;如果该方法返回一个负整数,则表明obj1小于obj2。
Java的一些常用类已经实现了Comparable接口,并提供了比较大小的标准。例如:
| 类 | 说明 |
|---|---|
| BigDecimal、BigInteger以及所有的数值类对应的包装类 | 按照它们对应的数值大小进行比较 |
| Character | 按字符的Unicode值进行比较 |
| Boolean | true对应的包装类实例大于false对应的包装类实例 |
| String | 按字符串中字符的Unicode值进行比较 |
| Date、Time | 后面的时间和日期比前面的时间和日期大 |
当一个对象加入TreeSet集合中时,TreeSet调用该对象的compareTo(Object obj)方法与容器中的其他对象比较大小,然后根据红黑树结果找到它的存储位置。如果两个对象通过compareTo(Object obj)方法比较相等,新对象将无法添加到TreeSet集合中。
由此应该注意到一个问题:当需要把一个对象放入TreeSet中,重写该对象对应类的equals()方法时,应保证该方法与compareTo(Object obj)方法有一致的结果,其规则是:如果两个对象通过equals()方法比较返回true时,这两个对象通过compareTo(Object obj)方法比较应该返回0。
如果两个对象通过compareTo(Object obj)方法比较返回0,但它们通过equals()方法比较返回false将会很麻烦,因为两个对象通过compareTo(Object obj)方法比较相等,TreeSet不会让第二个元素添加进去,这就会与Set集合的规则冲突。
我们可以做如下测试:
首先定义Person类,为了能够将Person类放进TreeSet中,需要实现Comparable接口,并重写其compareTo(Object obj)方法。还需要重写其hashCode()方法和equals()方法:
从上述代码可以看到,compareTo(Object obj)方法的比较标准是对象name属性的比较标准,也就是按照name属性字符串中字符的Unicode值进行比较,而equals()方法是按照四个属性是否相等来比较的。接着我们再做如下测试:
程序输出:
falsePerson [name=Anna, age=20, weight=55.0, height=165.0]Person [name=Jack, age=18, weight=78.5, height=178.5]p1和p2的name属性一样,都是”Jack”,但是其他属性都不一样。也就是equals()方法会返回false,但是p2却不能添加到我们定义的set中了,因为compareTo(Object obj)方法返回了true。
我们可以总结出如下结论:
(1)如果试图把一个对象添加到TreeSet中,则该对象的类必须实现Comparable接口,并重写其compareTo(Object obj)方法,否则程序将会抛出异常。 (2)如果希望TreeSet能够正常运行,TreeSet中只能添加同一种类型的对象。这样才能保证compareTo(Object obj)方法正常工作,否则会出现异常。 (3)要注意equals()方法与compareTo(Object obj)方法的规则 (4)与HashSet类似,如果要保证程序不出错,当对象放入TreeSet后,不要修改参与计算equals()方法和compareTo(Object obj)方法的关键实例变量!
TreeSet的自然排序是根据集合元素的大小,将它们按照升序进行排列。如果需要实现定制排序,例如以降序排列,则可以通过Comparator接口的帮助。该接口包含一个int compare(T o1, T o2)方法,该方法用于比较o1和o2的大小:如果该方法返回正整数,则表明o1大于o2;如果该方法返回0,则表明o1等于o2;如果该方法返回负整数,则表明o1小于o2。
如果需要实现定制排序,我们需要在创建TreeSet集合对象时,提供一个Comparator对象与该TreeSet集合关联,由该Comparator对象负责集合元素的排序逻辑。这时候,即使TreeSet中的对象对应的类实现了Comparable接口,在这里也不起作用了,或者干脆不实现Comparable接口也没有关系。
这里举一个例子,比如我们要将一个TreeSet<Integer>按照降序排列,则可以给该TreeSet提供一个自定义的Comparator对象,如下:
程序输出:
[8, 4, 1]对于所有Set集合的遍历,很显然,我们不能用普通的for循环,因为Set集合并不支持通过下标获取元素的Object get(index)方法。
我们可以采用foreach循环或者迭代器Iterator的方式:
TreeSet<Integer> set = new TreeSet<Integer>();set.add(1);set.add(2);set.add(3);for(Integer i : set){ System.out.println(i);}Iterator<Integer> it = set.iterator();while(it.hasNext()){ System.out.println(it.next());}新闻热点






疑难解答