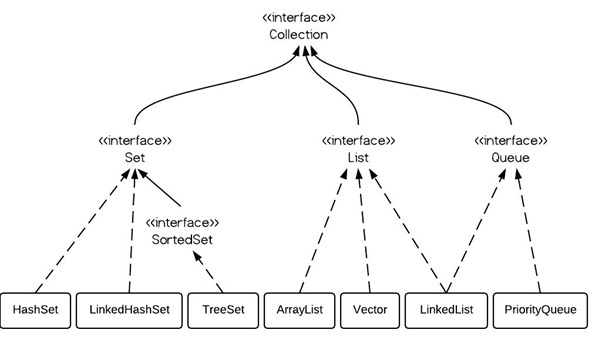
HashMap是一个最常用的Map,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序是完全随的。HashMap最多只允许一条记录的键为NULL,允许多条记录的值为NUll。HashMap不支持线程的同步,即任意时刻可以有多个线程同时写HashMap;可能会导致数据的不一致。如果需要同步,可以用Collections的synchronizedMap方法使HashMap具有同步的能力,或者使用ConcurrentHashMap。 1)HashMap的默认大小为16,即桶数组的默认长度为16。 2)HashMap的默认装载因子为0.75。 3)HashMap内部的桶数组存储的是Entry对象,也就是键值对对象。 4)构造器支持指定初始容量和装载因子,为避免数组扩容带来的性能问题,建议根据需求指定初始容量。装载因子尽量不要修改,0.75是个比较靠谱的值。 5)桶数组的长度始终是2的整数次方(大于等于指定的初始容量),这样做可以减少冲突概率,提高查找效率。 6)HashMap接受null键。 7)HashMap不允许键重复,但是值可以重复,若键重复,那么新值会覆盖旧值。 8)HashMap通过链表法解决冲突问题,每个Entry都有一个next指针指向下一个Entry,冲突元素(不是键相同,而是hash值相同)会构成一个链表。并且最新插入的键值对始终位于链表首部。 9)当容量超过阈值(threshold)时,会发生扩容,扩容后的数组是原数组的两倍。扩容操作需要开辟新数组,并对原数组中所有键值对重新散列,非常耗时。我们应该尽量避免HashMap扩容。 10)HashMap非线程安全。
Hashtable与HashMap类似,它继承自Dictionary类,不同的是,它不允许记录的键或者值为空;它支持线程的同步即任意时刻只有一个线程能写Hashtable,因此也导致了Hashtable在写入时会较慢;和HashMap一样,Hashtable取得数据的顺序也是无序的。 1)Hashtable是线程安全的类(HashMap非线程安全)。 2)Hashtable并不允许键和值为空(null),若为空,会抛出空指针(HashMap可以)。 3)Hashtable不允许键重复,若键重复,则新插入的值会覆盖旧值(同HashMap)。 4)Hashtable同样是通过链表法解决冲突的。 5)Hashtable根据hashcode计算索引时将hashcode值先与上0x7FFFFFFF,折是为了保证hash值始终为正数。 6)Hashtable的容量为任意正数(最小为1),而HashMap的容量始终为2的n次方。Hashtable默认容量为11,HashMap的默认容量为16。 7)Hashtable每次扩容,新容量为旧容量的2倍加2,而HashMap为旧容量的2倍。 8)Hashtable和HashMap默认负载因子都为0.75。
LinkedHashMap 1)LinkedHashMap继承自HashMap,具有HashMap的大部分特性,比如支持null键和值,默认容量为16,装载因子为0.75,非线程安全等等。 2)LinkedHashMap通过设置accessOrder控制遍历顺序是按照插入顺序(默认为false)还是按照访问顺序。当accessOrder为true时,可以利用其完成LRU缓存的功能。 3)LinkedHashMap内部维护了一个双向循环链表,并且其迭代操作是通过链表完成的,而不是去遍历hash表。
TreeMap实现SortMap接口,取出来的是排序后的键值对。但如果您要按自然顺序(默认,但是传入的类必须实现comparable借口,否则抛出ClassCastException)或自定义顺序(传入比较器)遍历键,那么TreeMap会更好。 1)TreeMap的实现基于红黑树。 2)TreeMap不允许插入null键,但允许null值。 3)TreeMap线程不安全。 4)插入结点时,若键重复,则新值覆盖旧值。 5)TreeMap要求Key必须实现Comparable接口,或者初始化时传入Comparator比较器。 6)遍历TreeMap得到的结果集是有序的(中序遍历);(红黑树是一种二叉排序树,而且是平衡树,中序遍历结果就是自然排序结果)。 7)TreeMap的各项操作的平均时间复杂度为O(logn)。
HashSet,TreeSet,LinkedHashSet分别建立了一个对应的HashMap,TreeMap,LinkedHashMap的实例,value存放的是同一个new Object(),方法完全调用对应Map的方法。
StringBuffer和StringBuilder 1)StringBuilders jdk1.5引进的,而StringBuffer在1.0就有了。 2)StringBuilder和StingBuffer都是可变的字符串,可以通过append或者insert等方法修改串的内容。 3)StingBuffer是线程安全的,而StringBuilder不是,因而在多线程的环境下优先使用StringBuffer,而其他情况下推荐使用StringBuilder,因为它更快。 4)StringBuilder和StringBuffer都继承自AbstractStingBuilder类,AbstractStringBuilder主要实现了扩容、append、inset方法,StringBuilder和StringBuffer的相关方法都直接调用的父类。 5)StringBuilder和StringBuffer的初始容量都是16,程序员尽量手动设置初始值,以避免多次扩容所带来的性能问题。 6)StringBuilder和StringBuffer的扩容机制:首先试着将当前数组容量扩充为原数组容量的2倍加上2,如果这个新容量仍然小于预定的最小值(minimunCapacity),那么久将新容量定为(minimumCapacity),最后判断是否溢出,若溢出,则将容量定位整型的最大值0x7fffffff。
ArrayList 1)ArrayList内部是通过一个Object数组实现的,当数组填满之后会根据需要进行扩容 2)最好预估ArrayList的大小,并设置其初始容量,以避免不必要的扩容所造成的性能问题。 3)ArrayList的初始容量是10,ArrayList每次扩容都将容量变为原来的1.5倍,若还小于所需的最小值,那么直接分配容量为所需值。 4)ArrayList线程不安全,允许空(null)的元素。 5)ArrayList内部有两个内部类,分别实现Iterator和ListIterator,定义了迭代的规则。
LinkedList 1)LinkedList内部通过双向链表实现。 2)LinkedList线程不安全,支持null元素。 3)LinkedList插入删除元素较方便,但是查找操作较耗时(对比ArrayList),虽然内部进行的优化(根据位置选择顺序还是逆序遍历,小于size>>2从头开始顺序查找,否则从末尾开始查找)。 4)LinkedList内部同样通过内部类的形式实现了迭代器(仅实现了ListIterator,iterator方法返回的也是ListIterator对象)。 5)LinkedList实现了Deque接口,可以当成栈,队列,双端队列来使用。
Vector和Stack 1)Vector是线程安全的类而ArrayList不是; 2)Vector的扩容基于扩容增量,若扩容增量不为0。每次扩容的大小都为原始容量加上扩容增量,若扩容增量为0,也就是默认的情况下,扩容大小为元素容量的两倍。 3)Vector默认大小为10。 4)Vector支持null(ArrayList也可以)。 5)Vector出来可以使用listIterator和iterator遍历集合,也可以使用Enumeration的方法遍历。 6)Stack类继承了Vector,并封装了栈的操作,同时也是一个线程安全的类。 7)从性能上看,推荐使用ArrayList和LinkedList而不使用Vector和Stack。
转自:http://svenliu.blog.163.com/blog/static/262873054201681743834691/
新闻热点






疑难解答