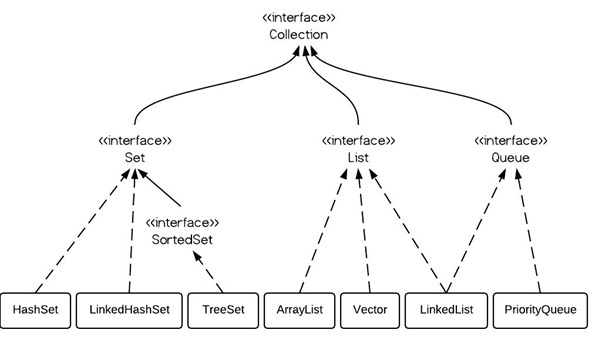
LinkedList作为实现了List接口的一个实现类,其底层采用双向链表的方式构建,相比于ArrayList可以更快的完成插入/删除操作,但是随机访问速度慢,并且可以方便的实现队列、栈等数据结构(更好的选择是ArrayDueue),LinkedList未实现同步,需要同步时采用Collections.synchronizedList()方法对其进行包装;
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.SerializableLinkedList的构造函数有以下两个:
public LinkedList() { }public LinkedList(Collection<? extends E> c) { this(); addAll(c);}默认构造方法,生成一个空的LinkedList,拷贝构造方法,用其他集合中得到一个LinkedList;LinkedList的操作主要有:在头/尾添加/删除元素、在任意位置添加/删除元素、得到/修改某位置元素的值、某元素在链表中的位置、链表长度等;
LinkedList中的结点用内部类Node实现:
PRivate static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }结点有指向前一个结点与后一个结点的指针,LinkedList还设置了头指针和尾指针,用于快速的完成对头/尾的操作;1. link方法 包括linkFirst:将一个结点连接到链表头部,考虑链表开始为空和不为空两种情况,连接完成后链表长度+1;
private void linkFirst(E e) { final Node<E> f = first; final Node<E> newNode = new Node<>(null, e, f); first = newNode; if (f == null) last = newNode; else f.prev = newNode; size++; modCount++; }linkLast:将一个结点连接到链表尾部,与上文方法一致;void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; }link:将一个结点连接到链表中间;void linkBefore(E e, Node<E> succ) { // assert succ != null; final Node<E> pred = succ.prev; final Node<E> newNode = new Node<>(pred, e, succ); succ.prev = newNode; if (pred == null) first = newNode; else pred.next = newNode; size++; modCount++; }同样有unlink的方法,unlinkFirst(),unlinkLast(),unLink()与上文类似;2. get方法 包括:getFirst() 得到链表头元素,会判断链表是否为空,getLast() 得到链表末尾元素,会判断链表是否为空;
3. remove方法类似,有removeFirst() ,removeLast();
public E removeFirst() { final Node<E> f = first; if (f == null) throw new NoSuchElementException(); return unlinkFirst(f); } public E removeLast() { final Node<E> l = last; if (l == null) throw new NoSuchElementException(); return unlinkLast(l); }4. add方法有addFirst() 和addLast() ;
public void addFirst(E e) { linkFirst(e); } public void addLast(E e) { linkLast(e); }5. size方法,得到链表现在的长度;
以上的方法均能在常数时间完成对链表的操作;6. clear方法:依次删除链表中的元素,直至链表为空,执行clear方法后链表会被回收;
public void clear() { // Clearing all of the links between nodes is "unnecessary", but: // - helps a generational GC if the discarded nodes inhabit // more than one generation // - is sure to free memory even if there is a reachable Iterator for (Node<E> x = first; x != null; ) { Node<E> next = x.next; x.item = null; x.next = null; x.prev = null; x = next; } first = last = null; size = 0; modCount++; }7. 链表的定位方法:Node<E> node(int index) { // assert isElementIndex(index); if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }返回某位置上的元素;public int indexOf(Object o) { int index = 0; if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) return index; index++; } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) return index; index++; } } return -1; }返回某元素第一次出现的位置,同理有返回元素最后一次出现的位置,就不再赘述;这两个查询方法是线性时间复杂度的,配合前面的方法就可以完成在任意位置的插入,删除,查询和修改了;
public E get(int index) { checkElementIndex(index); return node(index).item; }public E set(int index, E element) { checkElementIndex(index); Node<E> x = node(index); E oldVal = x.item; x.item = element; return oldVal; }public void add(int index, E element) { checkPositionIndex(index); if (index == size) linkLast(element); else linkBefore(element, node(index)); }public E remove(int index) { checkElementIndex(index); return unlink(node(index)); }checkElementIndex方法和checkPositionIndex方法用于判断index是不是一个有效值;8. LinkedList中封装了栈与队列的一些方法,如:peek方法,pop方法,push方法等,都是由上文提到的基本方法实现的;
9.LinkedList中有两个Iterator,分别负责正序遍历和反序遍历;
private class ListItr implements ListIterator<E> //正序遍历链表;private class DescendingIterator implements Iterator<E> //反序遍历链表;Iterator内部实现了next方法,hasnext等方法,对于用户而言,可以直接使用;对集合的遍历最好采用Iterator;
新闻热点






疑难解答