和HashMap一样,HashTable底层也是一个散列表(链表+数组),存储的内容为键值对(Key-Value)映射。 HashTable继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口。注意HashMap是继承AbstractMap类。 HashTable是同步的,意味着它是线程安全的。它的Key、Value值不允许为null;并且,HashTable存储的元素也不是有序的。 面试易考点:
| 关注点 | 结论 |
|---|---|
| 结合底层实现的数据结构 | 散列表(数组+列表) |
| 集合中元素是否允许为空 | Key允许为空,value不许为空 |
| 是否允许数据重复 | key值会被覆盖,value允许重复 |
| 是否有序 | 无序,是指不是按put进来的顺序 |
| 是否线程安全 | 线程安全(是同步synchronized的) |
1>基本特性 HashTable的实例有两个参数影响其性能:初始容量和加载因子。容量是指哈希表中桶的数量。初始容量就是哈希表初始化时的容量。注意。哈希表的状态为open:在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。加载因子是对哈希表在其容量自增得到的一个程度的描述。初始容量和加载因子这两个参数只是对该实现的提示。至于何时以及是否需要调用rehash方法,则依赖于具体实现。 一般,加载因子默认是0.75,这是在时间和空间复杂度上的一种最优选择。加载因子过高虽然减少了空间开销,但同时也增加了查找的时间(在大多数HashTable的实现中,包括get和put操作,都体现了这一点) 以上描述的与HashMap大致相同。 2>HashTable与Map关系如下图: 
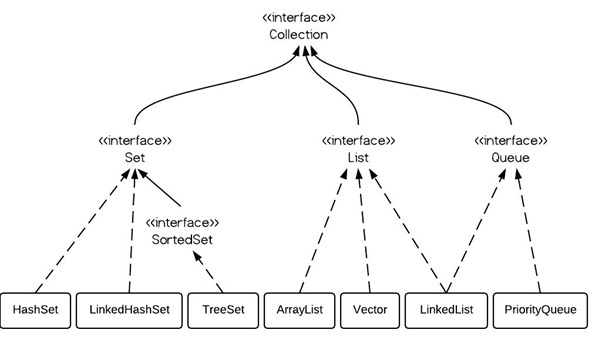
由上面的关系图得到: a. HashTable继承于Dictionary类(注意与HashMap的不同),实现了Map接口。Map是Key-Value键值对接口,Dictionary是声明了操作键值对的函数接口的抽象类。 b. HashTable是通过”拉链法”实现的哈希表。它包括几个重要的成员变量:table, count, threshold, loadFactor, modCount。 table:是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的”key-value键值对”都是存储在Entry数组中的; count:是Hashtable的大小,它是Hashtable保存的键值对的数量; threshold:是Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值=”容量*加载因子”; loadFactor:加载因子; modCount:是用来实现fail-fast机制的. 3>HashTable的构造函数
//指定容量大小和加载因子public HashTable(int initialCapacity, float loadFactor) { //校验输入参数 if (initialCapacity < 0) throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity); if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal Load: "+loadFactor); //当initialapacity输入为0时,默认设置成1 if (initialCapacity==0) initialCapacity = 1; this.loadFactor = loadFactor; //这里就是和hashMap不同的地方,hashMap是延迟加载,在第一次put的时候才new对象,HashTable这里是在构造器中直接new了。 table = new Entry[initialCapacity]; threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1); initHashSeedAsNeeded(initialCapacity);}//指定容量大小的构造函数public HashTable(int initialCapacity) { this(initialCapacity, 0.75f); } //默认构造函数 public Hashtable(){ this(11,0.75f); } //包含子Map的构造函数 public HashTable(Map<? extends K,? extends V> t){ this(Math.max(2*t.size(),11),0.75f); putAll(t); }其实常用方法和前一章的内容差不多,所以参照前面的内容进行分析 1>clear(): 用于清空HashTable。它是通过将所有的元素设为null来实现的。源码如下:
public synchronized void clear() { Entry tab[] = table; modCount++; for (int index = tab.length; --index >= 0; ) tab[index] = null; count = 0;}2>containsKey() 用于判断HashTable是否包含key。源码如下:
public synchronized boolean containsKey(Object key) { Entry tab[] = table; int hash = key.hashCode(); // 计算索引值, // % tab.length 的目的是防止数据越界 int index = (hash & 0x7FFFFFFF) % tab.length; // 找到“key对应的Entry(链表)”,然后在链表中找出“哈希值”和“键值”与key都相等的元素 for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { return true; } } return false;}3>containsValue()和containsValue() 都是用于判断HashTable是否包含“值为value”的元素,源码如下:
public boolean containsValue(Object value) { return contains(value);}public synchronized boolean contains(Object value) { // Hashtable中“键值对”的value不能是null, // 若是null的话,抛出异常! if (value == null) { throw new NullPointerException(); } // 从后向前遍历table数组中的元素(Entry) // 对于每个Entry(单向链表),逐个遍历,判断节点的值是否等于value Entry tab[] = table; for (int i = tab.length ; i-- > 0 ;) { for (Entry<K,V> e = tab[i] ; e != null ; e = e.next) { if (e.value.equals(value)) { return true; } } } return false;}4>elements() 用于返回“所有value”的枚举对象
public synchronized Enumeration<V> elements() { return this.<V>getEnumeration(VALUES);}// 获取Hashtable的枚举类对象PRivate <T> Enumeration<T> getEnumeration(int type) { if (count == 0) { return (Enumeration<T>)emptyEnumerator; } else { return new Enumerator<T>(type, false); }}从上面代码中,我们可以得到: 若Hashtable的实际大小为0,则返回空枚举类对象emptyEnumerator;否则返回正常的Enumerator对象。
5>get(object key) 用于获取key对应的value,若没找到则返回空。
public synchronized V get(Object key) { Entry tab[] = table; int hash = key.hashCode(); // 计算索引值, int index = (hash & 0x7FFFFFFF) % tab.length; // 找到“key对应的Entry(链表)”,然后在链表中找出“哈希值”和“键值”与key都相等的元素 for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { return e.value; } } return null;}6>put(K key,V value) 用于对外提供接口,让Hashtable对象可以通过put()将Key-Value键值对添加到Hashtable中,代码如下:
public synchronized V put(K key, V value) { // Hashtable中不能插入value为null的元素!!! if (value == null) { throw new NullPointerException(); } // 若“Hashtable中已存在键为key的键值对”, // 则用“新的value”替换“旧的value” Entry tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { V old = e.value; e.value = value; return old; } } // 若“HashTable中不存在键为key的键值对”, // (1) 将“修改统计数”+1 modCount++; // (2) 若“HashTable实际容量” > “阈值”(阈值=总的容量 * 加载因子) // 则调整HashTable的大小 if (count >= threshold) { // Rehash the table if the threshold is exceeded rehash(); tab = table; index = (hash & 0x7FFFFFFF) % tab.length; } // (3) 将“Hashtable中index”位置的Entry(链表)保存到e中 Entry<K,V> e = tab[index]; // (4) 创建“新的Entry节点”,并将“新的Entry”插入“Hashtable的index位置”,并设置e为“新的Entry”的下一个元素(即“新Entry”为链表表头)。 tab[index] = new Entry<K,V>(hash, key, value, e); // (5) 将“Hashtable的实际容量”+1 count++; return null;}7>putAll() 用于将已有Map中的全部元素逐一添加到HashTable中
public synchronized void putAll(Map<? extends K, ? extends V> t) { for (Map.Entry<? extends K, ? extends V> e : t.entrySet()) put(e.getKey(), e.getValue()); }8>remove(object key) 用于删除Hashtable中键值为key的元素
public synchronized V remove(Object key) { Entry tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; // 找到“key对应的Entry(链表)” // 然后在链表中找出要删除的节点,并删除该节点。 for (Entry<K,V> e = tab[index], prev = null ; e != null ; prev = e, e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { modCount++; if (prev != null) { prev.next = e.next; } else { tab[index] = e.next; } count--; V oldValue = e.value; e.value = null; return oldValue; } } return null;}1>遍历HashTable的键值对
// 假设table是Hashtable对象// table中的key是String类型,value是Integer类型Integer integ = null;Iterator iter = table.entrySet().iterator();while(iter.hasNext()) { Map.Entry entry = (Map.Entry)iter.next(); // 获取key key = (String)entry.getKey(); // 获取value integ = (Integer)entry.getValue();}2>通过Iterator遍历HashTable键值
// 假设table是Hashtable对象// table中的key是String类型,value是Integer类型String key = null;Integer integ = null;Iterator iter = table.keySet().iterator();while (iter.hasNext()) { // 获取key key = (String)iter.next(); // 根据key,获取value integ = (Integer)table.get(key);}3>通过Iterator遍历HashTable的值
// 假设table是HashTable对象// table中的key是String类型,value是Integer类型Integer value = null;Collection c = table.values();Iterator iter= c.iterator();while (iter.hasNext()) { value = (Integer)iter.next();}4>通过Enumeration遍历HashTable的键
Enumeration enu = table.keys();while(enu.hasMoreElements()) { System.out.println(enu.nextElement());}5>通过Enumeration遍历Hashtable的值
Enumeration enu = table.elements();while(enu.hasMoreElements()) { System.out.println(enu.nextElement());}从上面的代码可以看出,涉及到最多的是entrySet()、keySet()、value()、keys()、elements()等方法。 entrySet():获取Hashtable的“键值对”的Set集合; keySet():获取Hashtable的“键”的Set集合; value():获取Hashtable的“值”的集合; keys():获取Hashtable的集合; elements():获取Hashtable的集合。
运行结果如下:
table:{two=3, one=8, three=2}next : two - 3next : one - 8next : three - 2size:3contains key two : truecontains key five : falsecontains value 0 : falsetable:{two=3, one=8}table is empty文章只是作为自己的学习笔记,借鉴了网上的许多案例,如果觉得阔以的话,希望多交流,在此 谢过…
新闻热点






疑难解答