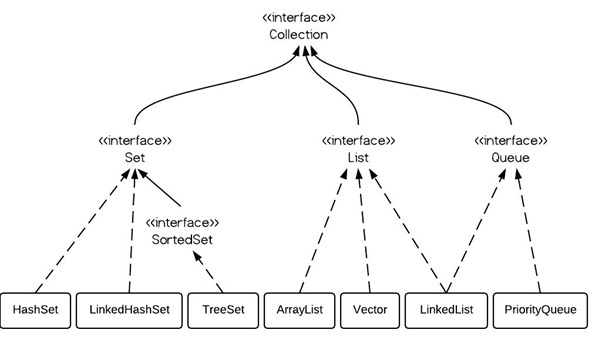
b.继承关系 Collection ├List │├LinkedList │├ArrayList │└Vector │ └Stack └Set Map ├Hashtable ├HashMap └WeakHashMap
b.继承关系 Collection ├List │├LinkedList │├ArrayList │└Vector │ └Stack └Set Map ├Hashtable ├HashMap └WeakHashMapb.LinkedList LinkedList是一个内部实现是基于链表的结构,节点定义代码 PRivate static class Node { E item; Node next; Node prev;
Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev;}} LinkedList 是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。 LinkedList 实现 List 接口,能对它进行队列操作。 LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。 LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。 LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。 LinkedList 是非同步的。
c.HashMap 本文来自:高爽|Coder,原文地址:http://blog.csdn.net/ghsau/article/details/16843543,转载请注明。 HashMap可以说是Java中最常用的集合类框架之一,是Java语言中非常典型的数据结构,我们总会在不经意间用到它,很大程度上方便了我们日常开发。在很多Java的笔试题中也会被问到,最常见的,“HashMap和HashTable有什么区别?”,这也不是三言两语能说清楚的,这种笔试题就是考察你来笔试之前有没有复习功课,随便来个快餐式的复习就能给出简单的答案。 HashMap计划写两篇文章,一篇是HashMap工作原理,也就是本文,另一篇是多线程下的HashMap会引发的问题。这一年文章写的有点少,工作上很忙,自己业余时间也做点东西,就把博客的时间占用了,以前是力保一周一篇文章,有点给自己任务的意思,搞的自己很累,文章质量也不高,有时候写技术文章也是需要灵感的,为了举一个例子可能要绞尽脑汁,为了一段代码可能要验证好多次,现在想通了,有灵感再写,需要一定的积累,才能把自己了解的知识点总结归纳成文章。 言归正传,了解HashMap之前,我们需要知道Object类的两个方法hashCode和equals,我们先来看一下这两个方法的默认实现:
/* JNI,调用底层其它语言实现 / public native int hashCode();
/* 默认同==,直接比较对象 / public boolean equals(Object obj) { return (this == obj); }
equals方法我们太熟悉了,我们经常用于字符串比较,String类中重写了equals方法,比较的是字符串值,看一下源码实现: public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String) anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; // 逐个判断字符是否相等 while (n– != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false; }
重写equals要满足几个条件:
自反性:对于任何非空引用值 x,x.equals(x) 都应返回 true。 对称性:对于任何非空引用值 x 和 y,当且仅当 y.equals(x) 返回 true 时,x.equals(y) 才应返回 true。 传递性:对于任何非空引用值 x、y 和 z,如果 x.equals(y) 返回 true,并且 y.equals(z) 返回 true,那么 x.equals(z) 应返回 true。 一致性:对于任何非空引用值 x 和 y,多次调用 x.equals(y) 始终返回 true 或始终返回 false,前提是对象上 equals 比较中所用的信息没有被修改。 对于任何非空引用值 x,x.equals(null) 都应返回 false。
Object 类的 equals 方法实现对象上差别可能性最大的相等关系;即,对于任何非空引用值 x 和 y,当且仅当 x 和 y 引用同一个对象时,此方法才返回 true(x == y 具有值 true)。 当此方法被重写时,通常有必要重写 hashCode 方法,以维护 hashCode 方法的常规协定,该协定声明相等对象必须具有相等的哈希码。 下面来说说hashCode方法,这个方法我们平时通常是用不到的,它是为哈希家族的集合类框架(HashMap、HashSet、HashTable)提供服务,hashCode 的常规协定是:
在 Java 应用程序执行期间,在同一对象上多次调用 hashCode 方法时,必须一致地返回相同的整数,前提是对象上 equals 比较中所用的信息没有被修改。从某一应用程序的一次执行到同一应用程序的另一次执行,该整数无需保持一致。 如果根据 equals(Object) 方法,两个对象是相等的,那么在两个对象中的每个对象上调用 hashCode 方法都必须生成相同的整数结果。 以下情况不 是必需的:如果根据 equals(java.lang.Object) 方法,两个对象不相等,那么在两个对象中的任一对象上调用 hashCode 方法必定会生成不同的整数结果。但是,程序员应该知道,为不相等的对象生成不同整数结果可以提高哈希表的性能。
当我们看到实现这两个方法有这么多要求时,立刻凌乱了,幸好有IDE来帮助我们,Eclipse中可以通过快捷键alt+shift+s调出快捷菜单,选择Generate hashCode() and equals(),根据业务需求,勾选需要生成的属性,确定之后,这两个方法就生成好了,我们通常需要在JavaBean对象中重写这两个方法。 好了,这两个方法介绍完之后,我们回到HashMap。HashMap是最常用的集合类框架之一,它实现了Map接口,所以存储的元素也是键值对映射的结构,并允许使用null值和null键,其内元素是无序的,如果要保证有序,可以使用LinkedHashMap。HashMap是线程不安全的,下篇文章会讨论。HashMap的类结构如下: java.util 类 HashMap java.lang.Object 继承者 java.util.AbstractMap 继承者 java.util.HashMap 所有已实现的接口: Serializable,Cloneable,Map 直接已知子类: LinkedHashMap,PrinterStateReasons HashMap中我们最长用的就是put(K, V)和get(K)。我们都知道,HashMap的K值是唯一的,那如何保证唯一性呢?我们首先想到的是用equals比较,没错,这样可以实现,但随着内部元素的增多,put和get的效率将越来越低,这里的时间复杂度是O(n),假如有1000个元素,put时需要比较1000次。实际上,HashMap很少会用到equals方法,因为其内通过一个哈希表管理所有元素,哈希是通过hash单词音译过来的,也可以称为散列表,哈希算法可以快速的存取元素,当我们调用put存值时,HashMap首先会调用K的hashCode方法,获取哈希码,通过哈希码快速找到某个存放位置,这个位置可以被称之为bucketIndex,通过上面所述hashCode的协定可以知道,如果hashCode不同,equals一定为false,如果hashCode相同,equals不一定为true。所以理论上,hashCode可能存在冲突的情况,有个专业名词叫碰撞,当碰撞发生时,计算出的bucketIndex也是相同的,这时会取到bucketIndex位置已存储的元素,最终通过equals来比较,equals方法就是哈希码碰撞时才会执行的方法,所以前面说HashMap很少会用到equals。HashMap通过hashCode和equals最终判断出K是否已存在,如果已存在,则使用新V值替换旧V值,并返回旧V值,如果不存在 ,则存放新的键值对到bucketIndex位置。文字描述有些乱,通过下面的流程图来梳理一下整个put过程。 现在我们知道,执行put方法后,最终HashMap的存储结构会有这三种情况,情形3是最少发生的,哈希码发生碰撞属于小概率事件。到目前为止,我们了解了两件事: HashMap通过键的hashCode来快速的存取元素。 当不同的对象hashCode发生碰撞时,HashMap通过单链表来解决,将新元素加入链表表头,通过next指向原有的元素。单链表在Java中的实现就是对象的引用(复合)。
来鉴赏一下HashMap中put方法源码:
public V put(K key, V value) { // 处理key为null,HashMap允许key和value为null if (key == null) return putForNullKey(value); // 得到key的哈希码 int hash = hash(key); // 通过哈希码计算出bucketIndex int i = indexFor(hash, table.length); // 取出bucketIndex位置上的元素,并循环单链表,判断key是否已存在 for (Entry e = table[i]; e != null; e = e.next) { Object k; // 哈希码相同并且对象相同时 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { // 新值替换旧值,并返回旧值 V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } }
// key不存在时,加入新元素 modCount++; addEntry(hash, key, value, i); return null;}
到这里,我们了解了HashMap工作原理的一部分,那还有另一部分,如,加载因子及rehash,HashMap通常的使用规则,多线程并发时HashMap存在的问题等等,这些会留在下一章说明。
d 总结 总结一:比较1 ,数组 (Array) ,数组类 (Arrays)
Java 所有“存储及随机访问一连串对象”的做法, array 是最有效率的一种。但缺点是容量固定且无法动态改变。 array 还有一个缺点是,无法判断其中实际存有多少元素, length 只是告诉我们 array 的容量。
Java 中有一个数组类 (Arrays) ,专门用来操作 array 。数组类 (arrays) 中拥有一组 static 函数。
equals() :比较两个 array 是否相等。 array 拥有相同元素个数,且所有对应元素两两相等。
fill() :将值填入 array 中。
sort() :用来对 array 进行排序。
binarySearch() :在排好序的 array 中寻找元素。
System.arraycopy() : array 的复制。
若编写程序时不知道究竟需要多少对象,需要在空间不足时自动扩增容量,则需要使用容器类库, array 不适用。
2 ,容器类与数组的区别
容器类仅能持有对象引用(指向对象的指针),而不是将对象信息 copy 一份至数列某位置。一旦将对象置入容器内,便损失了该对象的型别信息。
3 ,容器 (Collection) 与 Map 的联系与区别
Collection 类型,每个位置只有一个元素。
Map 类型,持有 key-value 对 (pair) ,像个小型数据库。
Collections 是针对集合类的一个帮助类。提供了一系列静态方法实现对各种集合的搜索、排序、线程完全化等操作。相当于对 Array 进行类似操作的类—— Arrays 。
如, Collections.max(Collection coll); 取 coll 中最大的元素。
Collections.sort(List list); 对 list 中元素排序List , Set , Map 将持有对象一律视为 Object 型别。
Collection 、 List 、 Set 、 Map 都是接口,不能实例化。继承自它们的 ArrayList, Vector, HashTable, HashMap 是具象 class ,这些才可被实例化。
vector 容器确切知道它所持有的对象隶属什么型别。 vector 不进行边界检查。
总结二:需要注意的地方
1 、 Collection 只能通过 iterator() 遍历元素,没有 get() 方法来取得某个元素。
2 、 Set 和 Collection 拥有一模一样的接口。但排除掉传入的 Collection 参数重复的元素。
3 、 List ,可以通过 get() 方法来一次取出一个元素。使用数字来选择一堆对象中的一个, get(0)… 。 (add/get)
4 、 Map 用 put(k,v) / get(k) ,还可以使用 containsKey()/containsValue() 来检查其中是否含有某个 key/value 。
HashMap 会利用对象的 hashCode 来快速找到 key 。
哈希码 (hashing) 就是将对象的信息经过一些转变形成一个独一无二的 int 值,这个值存储在一个 array 中。我们都知道所有存储结构中, array 查找速度是最快的。所以,可以加速查找。发生碰撞时,让 array 指向多个 values 。即,数组每个位置上又生成一个梿表。
5 、 Map 中元素,可以将 key 序列、 value 序列单独抽取出来。
使用 keySet() 抽取 key 序列,将 map 中的所有 keys 生成一个 Set 。
使用 values() 抽取 value 序列,将 map 中的所有 values 生成一个 Collection 。
为什么一个生成 Set ,一个生成 Collection ?那是因为, key 总是独一无二的, value 允许重复。
总结三:如何选择
从效率角度:
在各种 Lists ,对于需要快速插入,删除元素,应该使用 LinkedList (可用 LinkedList 构造堆栈 stack 、队列 queue ),如果需要快速随机访问元素,应该使用 ArrayList 。最好的做法是以 ArrayList 作为缺省选择。 Vector 总是比 ArrayList 慢,所以要尽量避免使用。
在各种 Sets 中, HashSet 通常优于 HashTree (插入、查找)。只有当需要产生一个经过排序的序列,才用 TreeSet 。 HashTree 存在的唯一理由:能够维护其内元素的排序状态。
在各种 Maps 中 HashMap 用于快速查找。
最后,当元素个数固定,用 Array ,因为 Array 效率是最高的。
所以结论:最常用的是 ArrayList , HashSet , HashMap , Array 。
本文很多摘抄自不同的地方,自己学习时根据jdk源码学习的,这里也为大家提供一种方法学习,常看源码
新闻热点






疑难解答