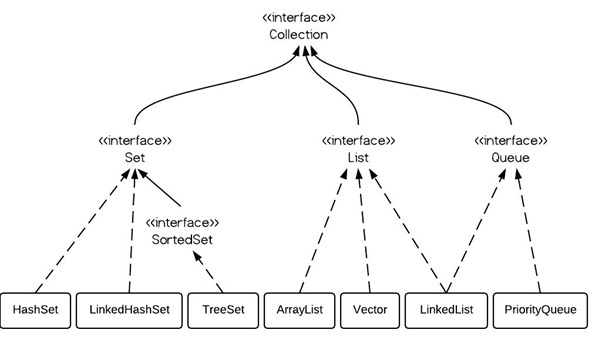
最近在想自己编程时是否注意过代码的效率问题,得出的答案是:没有。代码只是实现了功能,至于效率高不高没怎么关注,这应该是java程序员进阶的时候需要考虑的问题,不再是单纯的实现功能,也不是完全依赖GC而不关注内存中发生了什么,而要考虑到代码的性能。下面是网上找的一篇关于JAVA代码优化的文章,觉得不错,就” %>。该指令在编译时引入指定的资源。在编译之前,带有include指令的页面和指定的资源被合并成一个文件。被引用的外部资源在编译时就确定, 比运行时才确定资源更高效。 include动作:例如<jsp:include page=”copyright.jsp” />。该动作引入指定页面执行后生成的结果。由于它在运行时完成,因此对输出结果的控制更加灵活。但时,只有当被引用的内容频繁地改变时,或者在对 主页面的请求没有出现之前,被引用的页面无法确定时,使用include动作才合算。24、及时清除不再需要的会话 为了清除不再活动的会话,许多应用服务器都有默认的会话超时时间,一般为30分钟。当应用服务器需要保存更多会话时,如果内存容量不足,操作系统会把部分 内存数据转移到磁盘,应用服务器也可能根据“最近最频繁使用”(Most Recently Used)算法把部分不活跃的会话转储到磁盘,甚至可能抛出“内存不足”异常。在大规模系统中,串行化会话的代价是很昂贵的。当会话不再需要时,应当及时 调用Httpsession.invalidate()方法清除会话。HttpSession.invalidate()方法通常可以在应用的退出页面调 用。25、不要将数组声明为:public static final 。26、HashMap的遍历效率讨论 经常遇到对HashMap中的key和value值对的遍历操作,有如下两种方法:Map<String, String[]> paraMap = newHashMap<String, String[]>(); …………….//第一个循环 Set<String> appFieldDefIds = paraMap.keySet(); for (String appFieldDefId : appFieldDefIds) { String[] values = paraMap.get(appFieldDefId); …… }//第二个循环 for(Entry<String, String[]> entry : paraMap.entrySet()){ String appFieldDefId = entry.getKey(); String[] values = entry.getValue(); ……. }第一种实现明显的效率不如第二种实现。 分析如下 Set<String> appFieldDefIds = paraMap.keySet(); 是先从HashMap中取得keySet代码如下: public Set<K> keySet() { Set<K> ks = keySet; return (ks != null ? ks : (keySet = new KeySet())); }PRivate class KeySet extends AbstractSet<K> { public Iterator<K> iterator() { return newKeyIterator(); } public int size() { return size; } public boolean contains(Object o) { return containsKey(o); } public boolean remove(Object o) { return HashMap.this.removeEntryForKey(o) != null; } public void clear() { HashMap.this.clear(); } } 其实就是返回一个私有类KeySet, 它是从AbstractSet继承而来,实现了Set接口。再来看看for/in循环的语法 for(declaration : expression) statement在执行阶段被翻译成如下各式 for(Iterator<E> #i = (expression).iterator(); #i.hashNext();){ declaration = #i.next(); statement }因此在第一个for语句for (String appFieldDefId : appFieldDefIds) 中调用了HashMap.keySet().iterator()而这个方法调用了newKeyIterator()Iterator<K> newKeyIterator() { return new KeyIterator(); } private class KeyIterator extends HashIterator<K> { public K next() { return nextEntry().getKey(); } }所以在for中还是调用了在第二个循环for(Entry<String, String[]> entry : paraMap.entrySet())中使用的Iterator是如下的一个内部类private class EntryIterator extends HashIterator<Map.Entry<K,V>> { public Map.Entry<K,V> next() { return nextEntry(); } }此时第一个循环得到key,第二个循环得到HashMap的Entry效率就是从循环里面体现出来的第二个循环此致可以直接取key和value值 而第一个循环还是得再利用HashMap的get(Object key)来取value值现在看看HashMap的get(Object key)方法 public V get(Object key) { Object k = maskNull(key); int hash = hash(k); int i = indexFor(hash, table.length); //Entry[] table Entry<K,V> e = table; while (true) { if (e == null) return null; if (e.hash == hash && eq(k, e.key)) return e.value; e = e.next; } } 其实就是再次利用Hash值取出相应的Entry做比较得到结果,所以使用第一中循环相当于两次进入HashMap的Entry中而第二个循环取得Entry的值之后直接取key和value,效率比第一个循环高。其实按照Map的概念来看也应该是用第二个循环好一点,它本 来就是key和value的值对,将key和value分开操作在这里不是个好选择。27、array(数组) 和 ArryList的使用 array([]):最高效;但是其容量固定且无法动态改变; ArrayList:容量可动态增长;但牺牲效率; 基于效率和类型检验,应尽可能使用array,无法确定数组大小时才使用ArrayList! ArrayList是Array的复杂版本 ArrayList内部封装了一个Object类型的数组,从一般的意义来说,它和数组没有本质的差别,甚至于ArrayList的许多方法,如 Index、IndexOf、Contains、Sort等都是在内部数组的基础上直接调用Array的对应方法。 ArrayList存入对象时,抛弃类型信息,所有对象屏蔽为Object,编译时不检查类型,但是运行时会报错。 注:jdk5中加入了对泛型的支持,已经可以在使用ArrayList时进行类型检查。 从这一点上看来,ArrayList与数组的区别主要就是由于动态增容的效率问题了28、尽量使用HashMap 和ArrayList ,除非必要,否则不推荐使用HashTable和Vector ,后者由于使用同步机制,而导致了性能的开销。
新闻热点






疑难解答