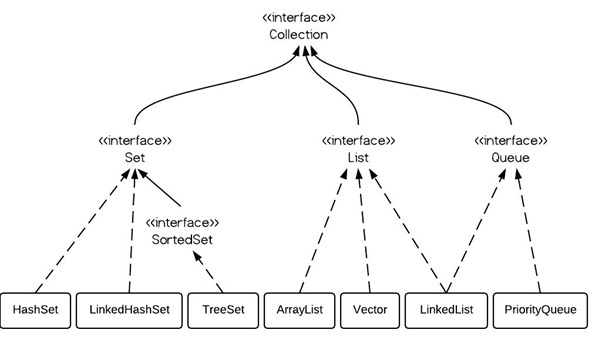
正如我之前所写的,java 8中的新功能特性改变了游戏规则。对Java开发者来说这是一个全新的世界,并且是时候去适应它了。
在这篇文章里,我们将会去了解传统循环的一些替代方案。在Java 8的新功能特性中,最棒的特性就是允许我们去表达我们想要完成什么而不是要怎样做。这正是循环的不足之处。要确保循环的灵活性是需要付出代价的。return、break 或者 continue都会显著地改变循环的实际表现。这迫使我们不仅要清楚我们要实现怎样的代码,还要了解循环是怎样工作的。
在介绍Java 8的流(Stream)时,我们学会了一些集合操作的实用技巧。现在我们要看看怎样把这些循环转换为更简洁,可读性更高的代码。

好吧,讲的够多了,是时候展示一些例子了!
这次我们要以文章为例子。一篇文章拥有一个标题,一个作者和几个标签。
| 123456789101112131415161718192021222324 | PRivateclassArticle { privatefinalString title; privatefinalString author; privatefinalList<String> tags; privateArticle(String title, String author, List<String> tags) { this.title = title; this.author = author; this.tags = tags; } publicString getTitle() { returntitle; } publicString getAuthor() { returnauthor; } publicList<String> getTags() { returntags; } } |
每个例子都会包含一个使用传统循环的方案和一个使用Java 8新特性的方案。
在第一个例子里,我们要在集合中查找包含“Java”标签的第一篇文章。
看一下使用for循环的解决方案。
| 12345678910 | publicArticle getFirstJavaArticle() { for(Article article : articles) { if(article.getTags().contains("Java")) { returnarticle; } } returnnull;} |
现在我们使用Stream API的相关操作来解决这个问题。
| 12345 | publicOptional<Article> getFirstJavaArticle() { returnarticles.stream() .filter(article -> article.getTags().contains("Java")) .findFirst(); } |
是不是很酷?我们首先使用 filter 操作去找到所有包含Java标签的文章,然后使用 findFirst() 操作去获取第一次出现的文章。因为Stream是“延迟计算”(lazy)的并且filter返回一个流对象,所以这个方法仅在找到第一个匹配元素时才会处理元素。
现在,让我们获取所有匹配的元素而不是仅获取第一个。
首先使用for循环方案。
| 123456789101112 | publicList<Article> getAllJavaArticles() { List<Article> result = newArrayList<>(); for(Article article : articles) { if(article.getTags().contains("Java")) { result.add(article); } } returnresult;} |
使用Stream操作的方案。
| 12345 | publicList<Article> getAllJavaArticles() { returnarticles.stream() .filter(article -> article.getTags().contains("Java")) .collect(Collectors.toList()); } |
在这个例子里我们使用 collection 操作在返回流上执行少量代码而不是手动声明一个集合并显式地添加匹配的文章到集合里。
到目前为止还不错。是时候举一些突出Stream API强大的例子了。
根据作者来把所有的文章分组。
照旧,我们使用循环方案。
| 12345678910111213141516 | publicMap<String, List<Article>> groupByAuthor() { Map<String, List<Article>> result = newHashMap<>(); for(Article article : articles) { if(result.containsKey(article.getAuthor())) { result.get(article.getAuthor()).add(article); }else{ ArrayList<Article> articles = newArrayList<>(); articles.add(article); result.put(article.getAuthor(), articles); } } returnresult;} |
我们能否找到一个使用流操作的简洁方案来解决这个问题?
| 1234 | publicMap<String, List<Article>> groupByAuthor() { returnarticles.stream() .collect(Collectors.groupingBy(Article::getAuthor));} |
很好!使用 groupingBy 操作和 getAuthor 方法,我们得到了更简洁、可读性更高的代码。
现在,我们查找集合中所有不同的标签。
我们从使用循环的例子开始。
| 12345678910 | publicSet<String> getDistinctTags() { Set<String> result = newHashSet<>(); for(Article article : articles) { result.addAll(article.getTags()); } returnresult;} |
好,我们来看看如何使用Stream操作来解决这个问题。
| 12345 | publicSet<String> getDistinctTags() { returnarticles.stream() .flatMap(article -> article.getTags().stream()) .collect(Collectors.toSet());} |
棒极了!flatmap 帮我把标签列表转为一个返回流,然后我们使用 collect 去创建一个集合作为返回值。
以上的就是如何使用可读性更高的代码代替循环的例子。务必仔细看看Stream API,因为这篇文章仅仅提到它的一些皮毛而已。
更新了getDistinctTags()例子,使用集合(Set)作为返回集合。
原文链接: deadcoderising 翻译: ImportNew.com - 进林译文链接: http://www.importnew.com/14841.html[ 转载请保留原文出处、译者和译文链接。]新闻热点






疑难解答