在《R语言的数据对象》一文中提到,R语言的数据对象从结构角度划分,可以分为向量、数组、矩阵、因子、列表和数据框6种。本文首先探讨一下R语言中向量的使用方法。
在R语言中,向量(Vector)是相同基本类型元素组成的序列,相当于一维数组。
向量的元素可以是数值型、字符型、逻辑值型和复数型,对应分别称为数值型向量、字符串型向量、逻辑型向量和复数型向量。
向量中可以包含一个元素,也可以包含多个元素。
同一个向量中的数据类型应该相同。
1、向量的创建
(1)直接创建
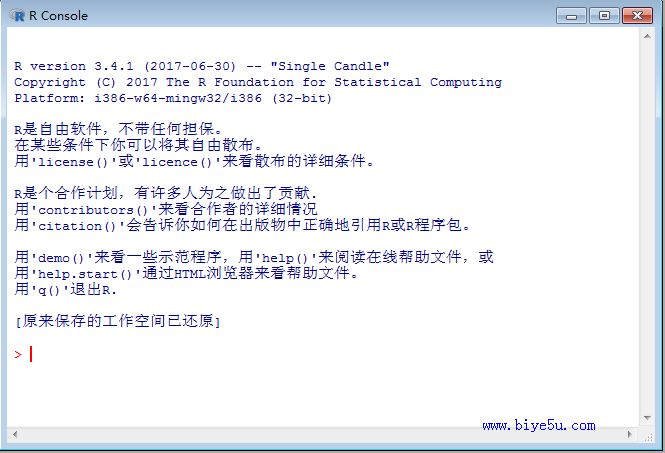
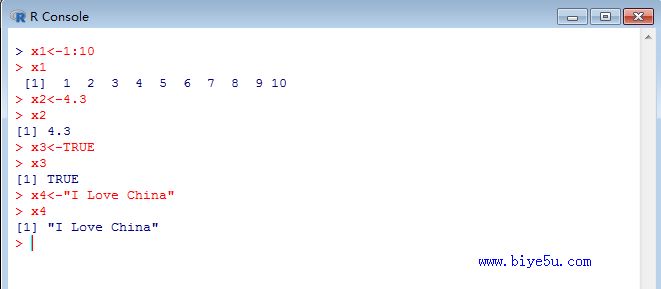
x1<-1:10 #输出:[1] 1 2 3 4 5 6 7 8 9 10
x2<-4.3 #只包含一个值的向量
x3<-TRUE #逻辑型向量,注意在R中,TRUE和FALSE必须大写
x4 <- "I Love China" #字符串型向量
在R语言中,<-表示赋值,即右侧的值赋给左侧的变量。在R语言中,->的写法也是正确的,即把左侧的赋给右侧的变量。但等号=不是R语言的标准语法,在有些情况下可能会出现问题,不建议使用。
在R语言中#是注释符,即#后面的内容是注释的内容,是对该行内容的一个解释。
本部分在Windows R3.4.1中的执行情况见下图:
(2)使用c()函数创建
使用c()函数可以创建多个值的向量
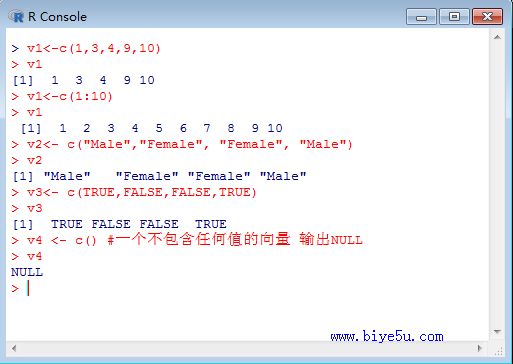
v1 <- c(1,3,4,9,10) #输出1 3 4 9 10
v1 <- c(1:10) #创建1到10的向量 输出:1 2 3 4 5 6 7 8 9 10
v2<- c("Male","Female", "Female", "Male") #字符串型向量
v3<- c(TRUE,FALSE,FALSE,TRUE) #逻辑型向量
v4 <- c() #一个不包含任何值的向量 输出NULL
在R语言中,c()函数可以有任意多个参数。
本部分的执行情况见下图:
(3)使用seq函数生成等差序列的向量
seq函数的原型如下:
seq(from=1,to=1,by=((to-from)/(length.out - 1)),length.out = NULL,along.with = NULL,...)
其中,from是首项,默认为1;to是末项,默认为1;by是步长或等差增量,可以为负数;length.out是向量的长度;along.with:用于指明该向量与另外一个向量的长度相同,along.with后应为另外一个向量的名字。
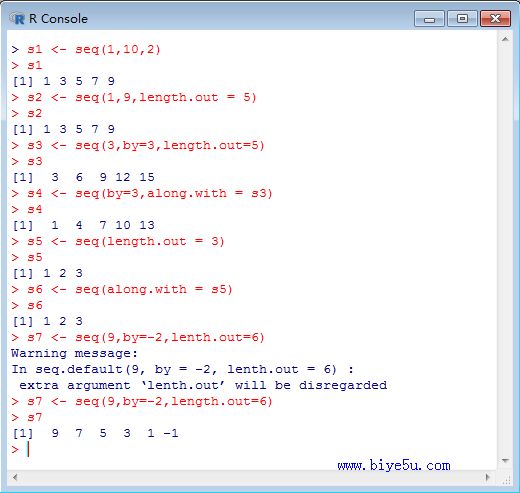
s1 <- seq(1,10,2) #向量从1开始,步长为2,最大不超过10,这里输出:1 3 5 7 9
s2 <- seq(1,9,length.out = 5) # 输出1 3 5 7 9,这里的步长是根据(9 - 1)/(5-1)计算出来的
s3 <- seq(3,by=3,length.out=5) #输出3 6 9 12 15
s4 <- seq(by=3,along.with = s3) #输出1 4 7 10 13,未指定from项时,默认从1开始,长度与向量s3相同
s5 <- seq(length.out = 3) #输出1 2 3
s6 <- seq(along.with = s5) #输出 1 2 3
s7 <- seq(9,by=-2,length.out=6) # 9 7 5 3 1 -1
进一步说明:这里的from, to,by项可以为任意实数,即也可以为浮点数。
本部分的执行情况见下图:
(4)使用rep函数创建重复序列的向量
rep函数可以将某一向量重复若干次,该函数的原型如下:
rep(x , times = 1, length.out = NA, each = 1)
参数中,x为要重复的序列对象;times为重复的次数,默认为1;length.out为产生的向量长度,默认为NA(未限制);each为每个元素重复的次数,默认为1。
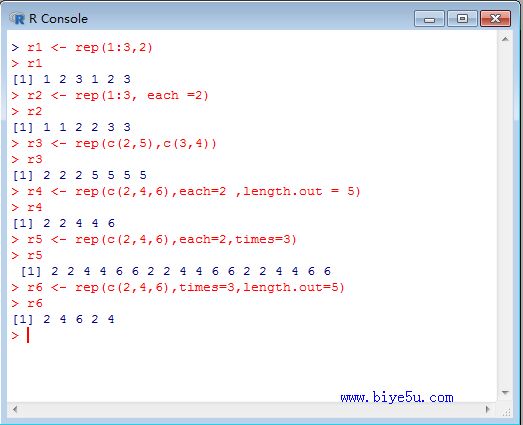
r1 <- rep(1:3,2) #输出: 1 2 3 1 2 3 前面的序列按原顺序重复2次
r2 <- rep(1:3, each =2) # 输出 1 1 2 2 3 3 序列中的每个元素重复2次
r3 <- rep(c(2,5),c(3,4)) #输出2 2 2 5 5 5 5 5将向量c(2, 5)按照后面给出的次数向量依次重复3次和4次
r4 <- rep(c(2,4,6),each=2 ,length.out = 5) #输出2 2 4 4 6 由于规定长度为5,这里仅有5项
r5 <- rep(c(2,4,6),each=2,times=3) #输出2 2 4 4 6 6 2 2 4 4 6 6 2 2 4 4 6 6 每项2次,整体3次
r6 <- rep(c(2,4,6),times=3,length.out=5) #输出2 4 6 2 4 整体应该重复3次,但这里规定了长度,所以只有5项
本部分的执行情况见下图:
2、为向量的每个元素命名
vn <- c(11,22,33,44)
names(vn) <- c("one","two","three","four") #对应元素的名字分别为one, two, three, four
本部分的执行情况见下图:
3、向量的引用
vc <- c(11,22,33,44,55,66) #创建一个向量
(1)使用元素的位置引用
① vc[1] #提取第一个元素值:11
② vc[1:3] #提取1~3个元素的值:11 22 33
③ vc[c(2,4,5)] #提取第2、第4和第5个元素的值:22 44 55
④ vc[-1] #提取除第一个元素之外的元素值:22 33 44 55 66
⑤ vc[-(1:3)] #提取除1~3个元素之外的元素值:44 55 66
⑥ vc[-c(2,4,5)] #提取除第2、第4和第5个之外的元素值:11 33 66
(2)使用逻辑向量
⑦ vc[c(TRUE,TRUE,FALSE,FALSE,TRUE,FALSE)] #提取对应位置为TRUE的元素值:11 22 55
⑧ vc[c(TRUE,FALSE)] #输出11 33 55 这里的c(TRUE,FALSE)自动补齐到与vc向量长度相同,c(TRUE,FALSE,TRUE,FALSE,TRUE,FALSE)
⑨ vc[c(TRUE,TRUE,FALSE)] #输出11 22 44 55
(3)使用元素名字
names(vc) <- c("one","two","three","four","five","six") #为每个元素命名为one,two,three,four,five,six
⑩ vc["one"] #输出11(在此值上方会有其名字one) 这种方法只能用于访问一个元素的情况
⑪vc[c("one","three","six")] #输出11 33 66 (其上方会带有其对应的名字)
(4)使用which函数进行筛选
⑫which(vc==11) # 找出向量vc中元素值为11的元素位置:这里输出1,即11在vc中的位置为1
⑬which(vc==11|vc==33)) #找出向量vc中元素值为11或33的元素所在位置:1 3
⑭which(vc>11 & vc<=44)#找出元素值大于11且小于44的元素所在位置:2 3 4
⑮which.max(vc) #最大元素值所在的位置:6
⑯which.min(vc) #最小元素所在的位置:1
(5)使用subset函数索引
可以使用subset函数找出向量中满足给定条件的向量元素值,语法格式如下:
subset(向量名,逻辑条件)
⑰subset(vc,vc>11 & vc<55) #得到 22 33 44
⑱subset(vc,c(TRUE,FALSE,TRUE)) #11 33 44 66 逻辑向量通过重复自动补齐
(6)match函数
该函数的原型为:
match(x,y)
该函数返回的是x中的每个元素在y中对应的位置,如果x中的元素在y中不存在,则该位置返回NA
⑲match(vc,c(11,22)) # 1 2 NA NA NA NA 因为x中的33 44 55 66在c(11,22)中不存在,所以后面4个为NA
⑳match(vc,c(11,33,55,66,88,99)) # 1 NA 2 NA 3 4 vc中的22在给定的序列中不存在所以第2个为NA,33在给定的序列位置为2,所以vc中的第3个元素位置为2...
4、向量的编辑
(1)扩展向量
vc<-c(11,22,33,44) #创建一个向量
vc <-c(vc,c(55,66)) #给vc扩展,增加了2个元素55和66
vc <- append(vc,77) #在向量最后追加一个新元素77
vc <- append(vc,c(88,99)) #在向量后追加连个元素88和99
vc<- append(vc,100,3) #在第3个元素后追加一个新元素100 :11 22 33 100 44 55 66 77 88 99
说明,使用append追加元素会生成一个新的向量,不是直接在原向量中追加,看下面的例子:
vc<- c(11,22,33)
append(vc,c(44,55))
若重新输出vc,会发现vc的向量值元素仍然为:11 22 33,并没有发生变化
只有这样vc <- append(vc,c(44,55)),重新打印vc的值为:11 22 33 44 55
(2)改变元素的值
vc[1] <- 111 #向量vc的第一个元素值变为111
vc[1:3] <- 111 #向量vc中第1~第3个元素的值都变为111
vc[1:3] <- c(111,222,333) #向量vc中第1~第3个元素的值分别被修改为111 222 333
vc[vc>33] <- 11 #将向量vc中的所有元素值大于33的元素值修改为11
vc[vc==33] <- 11 #将向量vc中元素值为33的元素值修改为11
(3)删除元素
vc<-vc[-1] #从vc中删除了位置为1的元素
vc<-vc[-c(3:5)] #从vc中删除了位置为3,4,5的元素
vc<-vc[c(2:4)] #删除了出位置为2,3,4之外的元素
5、向量的排序
(1)sort函数
sort函数原型如下:
sort(x, decreasing=FALSE,na.last = NA,index.return = FALSE,...)
x为要排序的对象,decreasing为排序顺序,是否为降序,默认为FALSE,即升序;na.last是对NA(mising value 或者Not available)值的处理,若为TRUE,则NA值将放在最后,若为FALSE,NA值将放在最前面,若为NA,则排序时剔除掉NA值;index.return是个逻辑值,设置是否显示排序序列对应的元素值在未排序前序列中的对应位置索引,默认为FALSE。
sort可以使用的的形式如下:
sort(vc) #默认升序排序,NA值不参与排序,且被剔除掉,即若vc中有NA值的话,排序后的序列中不含有NA值
sort(vc,decreasing = TRUE) #降序排序,NA值默认被剔除掉
sort(vc,na.last = TRUE) #默认升序排序,NA值不被剔除掉,且放在排序序列的后面
注意:排序生成新的序列,不会影响原向量的值及顺序
(2)rev函数
rev函数将向量倒序,即将原向量的元素按位置翻转
vc <- c(11,44,33,22,77,66) #创建一个向量
rev(vc) #66 77 22 33 44 11
6、用于向量的一些函数
(1)求和函数sum()
v <- c(1:10) #创建一个新向量:1 2 3 4 5 6 7 8 9 10
sum(vc) # 55
(2)求最大值函数max()
max(v) # 10
(3)求最小值函数min()
min(v) # 1
(4)求均值函数mean()
mean(v) # 5.5
(5)求中位数函数median()
median(v) # 5.5
v1<- c(1:9) # 创建一个新向量:1 2 3 4 5 6 7 8 9
median(v1) # 5
(6)range()函数
相当于c(min(x), max(x))
range(v) # 1 10
range(v1) #1 9
(7)求方差函数var()
var(v) #9.166667
var(v1) # 7.5
(8)求标准差函数 sd()
sd(v) #3.02765
sd(v1) #2.738613
(9)求向量元素值连乘积prod()
prod(v) #3628800
prod(v1) #362880
(10)累加和向量函数cumsum(x)
结果是一个向量,长度与x相同,每一项的值是该项与前一项累加后的值
cumsum(v1) #1 3 6 10 15 21 28 36 45
cumsum(v) #1 3 6 10 15 21 28 36 45 55
(完)
新闻热点






疑难解答