前言
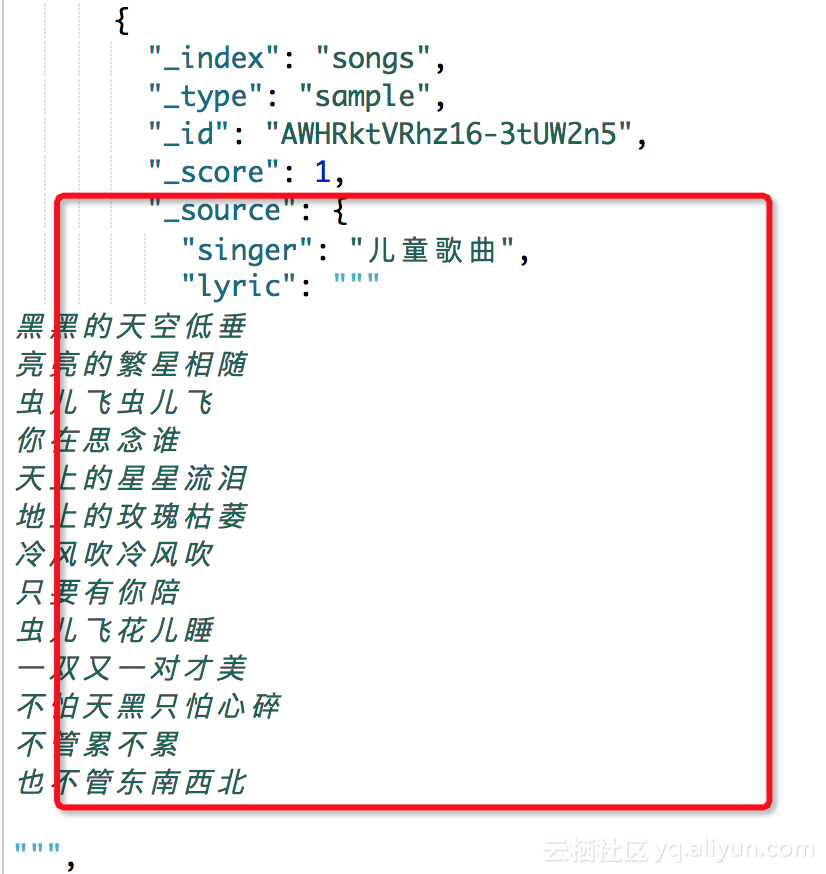
好久没有更新博客了,今天和大家分享一个关于emoji表情持久化问题,相信做web开发的都遇到过这样的问题,因为我们知道mysql的utf-8字符集保存不了保存不了表情字符,这是为什么呢?因为普通的字符串或者表情都是占位3个字节,所以utf8足够用了,但是移动端的表情符号占位是4个字节,普通的utf8就不够用了,为了应对无线互联网的机遇和挑战、避免 emoji 表情符号带来的问题、涉及无线相关的 MySQL 数据库建议都提前采用 utf8mb4 字符集,这必须要作为移动互联网行业的一个技术选型的要点。
好了看到上面的结果你是不是已经去修改数据库字符集了,如果你是个人项目或小项目上面的方法倒是一个解决方法,但是对于一个目前正在服务5000W用户的系统,上面的方式就有点不合适了,针对这种情况我这边总结了三种处理方式,下面分享给大家:
1、既然是由于移动端的表情符号占位是4个字节,那我们直接把数据转换后保存。
1.URLEncoder.encode(String s, String enc)
使用指定的编码机制将字符串转换为 application/x-www-form-urlencoded 格式
URLDecoder.decode(String s, String enc)
使用指定的编码机制对 application/x-www-form-urlencoded 字符串解码。
2、方法一的处理太粗躁,有没有更好的解决办法呢?使用轻量级工具emoji-java处理emoji表情字符
github地址:https://github.com/vdurmont/emoji-java
具体使用方式,大家可以进入git中自行查看。
3、有了上面两种方式,你是不是已经满足了,最为自己最推崇的emoji处理方式,下面才是重点,首先说一下上面两种方式存在的问题:第一种方式,数据经过转换,相当于加密,我们将无法直接查看到数据的原始内容,由其对于需要进行搜索的业务场景,将是一件很困难的事情;第二种方式,虽然避免了第一种方式存在的问题,但是它基于表情的对照表进行匹配转换的,也就意味着对于一些新表情,无法做到转换,这就会导致我们数据插入继续出现问题,这是它第一个问题,第二点在于它将表情转化为对应的匹配规则,说白一点就是转化为英文描述,就是这个转化,原本4个字节的表情,它可能给你转成了10个字节甚至更多。好了说了这么多下面我们看一下我最后的终极解决方法:
/** * @Author: gaoshang * @Description: * @Date: 2019/7/19 */public class EmojiUtil { /** * 将文本中的表情转为十六进制 * <p> * * @param input * @return */ public static String parseFromAliases(String input) { if (input == null) { return input; } return stringToUnicode(input); } /** * 将文本中的十六进制转为表情 * <p> * * @param input * @return */ public static String parseToAliases(String input) { if (input == null) { return input; } return unicodeToString(input); } /** * 字符串转unicode * * @param str * @return */ public static String stringToUnicode(String str) { StringBuilder sb = new StringBuilder(); StringBuilder cacheSB = new StringBuilder(); char[] c = str.toCharArray(); for (int i = 0; i < c.length; i++) { if (!isEmojiCharacter(c[i])) { if (cacheSB.length() > 0) { sb.append("//u").append(cacheSB); cacheSB.delete(0, cacheSB.length()); } sb.append("//u").append("[").append(Integer.toHexString(c[i])).append("]"); } else { if (c[i] == '[' || c[i] == '//' || c[i] == ']') { if (cacheSB.length() > 0) { sb.append("//u").append(cacheSB); cacheSB.delete(0, cacheSB.length()); } sb.append("//u").append(c[i]); } else { cacheSB.append(c[i]); } } } if (cacheSB.length() > 0) { if (sb.length() > 0) { sb.append("//u"); } sb.append(cacheSB); } return sb.toString(); } /** * unicode转字符串 * * @param unicode * @return */ public static String unicodeToString(String unicode) { StringBuilder sb = new StringBuilder(); String[] hex = unicode.split("////u"); for (int i = 0; i < hex.length; i++) { if (hex[i].indexOf("[") == 0 && hex[i].indexOf("]") == hex[i].length() - 1) { try { int index = Integer.parseInt(hex[i].substring(1, hex[i].length() - 1), 16); sb.append((char) index); } catch (NumberFormatException e) { sb.append(hex[i]); } } else { sb.append(hex[i]); } } return sb.toString(); } private static boolean isEmojiCharacter(char codePoint) { return (codePoint == 0x0) || (codePoint == 0x9) || (codePoint == 0xA) || (codePoint == 0xD) || ((codePoint >= 0x20) && (codePoint <= 0xD7FF)) || ((codePoint >= 0xE000) && (codePoint <= 0xFFFD)) || ((codePoint >= 0x10000) && (codePoint <= 0x10FFFF)); }}好了就先这样,欢迎大家提出不同的看法,已经好的解决方案。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持武林网。
新闻热点






疑难解答