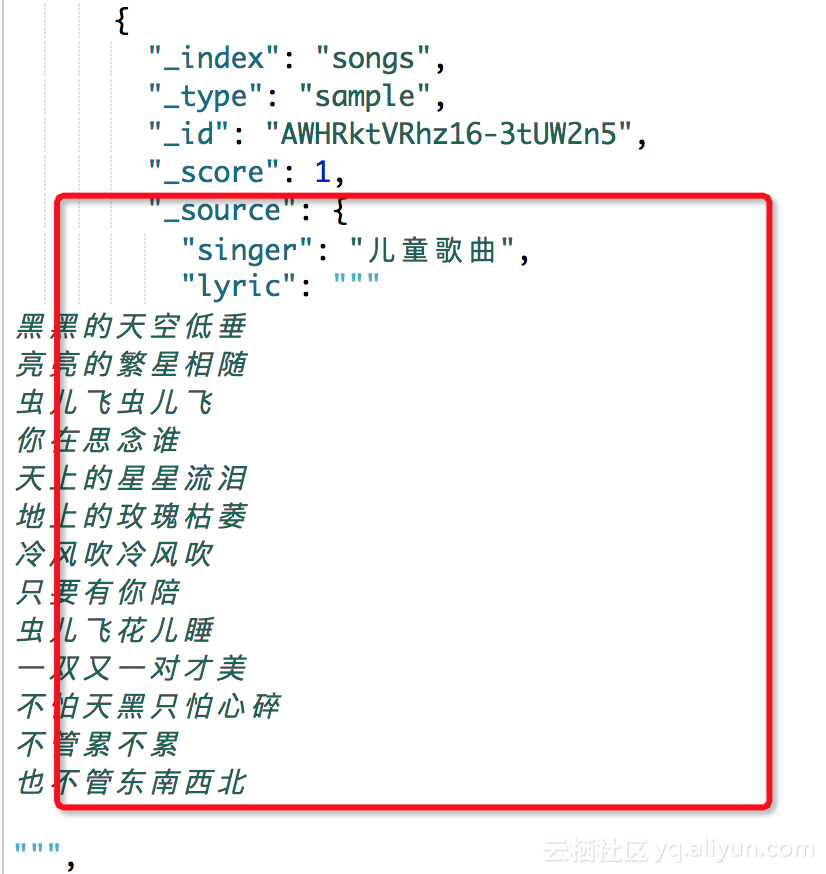
首先看下我们要分析的代码段如下:

输出结果如下:

输出结果(a).PNG

输出结果(b).PNG

输出结果(c).PNG
括号里是一个二元式:(单词类别编码,单词位置编号)
代码如下:
package Yue.LexicalAnalyzer;import java.io.*;/* * 主程序 */public class Main { public static void main(String[] args) throws IOException { Lexer lexer = new Lexer(); lexer.printToken(); lexer.printSymbolsTable(); }}package Yue.LexicalAnalyzer;import java.io.*;import java.util.*;/* * 词法分析并输出 */public class Lexer { /*记录行号*/ public static int line = 1; /*存放最新读入的字符*/ char character = ' '; /*保留字*/ Hashtable<String, KeyWord> keywords = new Hashtable<String, KeyWord>(); /*token序列*/ private ArrayList<Token> tokens = new ArrayList<Token>(); /*符号表*/ private ArrayList<Symbol> symtable = new ArrayList<Symbol>(); /*读取文件变量*/ BufferedReader reader = null; /*保存当前是否读取到了文件的结尾*/ private Boolean isEnd = false; /* 是否读取到文件的结尾 */ public Boolean getReaderState() { return this.isEnd; } /*打印tokens序列*/ public void printToken() throws IOException { FileWriter writer = new FileWriter("E://lex.txt"); System.out.println("词法分析结果如下:"); System.out.print("杜悦-2015220201031/r/n/n"); writer.write("杜悦-2015220201031/r/n/r/n"); while (getReaderState() == false) { Token tok = scan(); String str = "line " + tok.line + "/t(" + tok.tag + "," + tok.pos + ")/t/t" + tok.name + ": " + tok.toString() + "/r/n"; writer.write(str); System.out.print(str); } writer.flush(); } /*打印符号表*/ public void printSymbolsTable() throws IOException { FileWriter writer = new FileWriter("E://symtab1.txt"); System.out.print("/r/n/r/n符号表/r/n"); System.out.print("编号/t行号/t名称/r/n"); writer.write("符号表/r/n"); writer.write("编号 " + "/t行号 " + "/t名称 /r/n"); Iterator<Symbol> e = symtable.iterator(); while (e.hasNext()) { Symbol symbol = e.next(); String desc = symbol.pos + "/t" + symbol.line + "/t" + symbol.toString(); System.out.print(desc + "/r/n"); writer.write(desc + "/r/n"); } writer.flush(); } /*打印错误*/ public void printError(Token tok) throws IOException{ FileWriter writer = new FileWriter("E://error.txt"); System.out.print("/r/n/r/n错误词法如下:/r/n"); writer.write("错误词法如下:/r/n"); String str = "line " + tok.line + "/t(" + tok.tag + "," + tok.pos + ")/t/t" + tok.name + ": " + tok.toString() + "/r/n"; writer.write(str); } /*添加保留字*/ void reserve(KeyWord w) { keywords.put(w.lexme, w); } public Lexer() { /*初始化读取文件变量*/ try { reader = new BufferedReader(new FileReader("E://输入.txt")); } catch (IOException e) { System.out.print(e); } /*添加保留字*/ this.reserve(KeyWord.begin); this.reserve(KeyWord.end); this.reserve(KeyWord.integer); this.reserve(KeyWord.function); this.reserve(KeyWord.read); this.reserve(KeyWord.write); this.reserve(KeyWord.aIf); this.reserve(KeyWord.aThen); this.reserve(KeyWord.aElse); } /*按字符读*/ public void readch() throws IOException { character = (char) reader.read(); if ((int) character == 0xffff) { this.isEnd = true; } } /*判断是否匹配*/ public Boolean readch(char ch) throws IOException { readch(); if (this.character != ch) { return false; } this.character = ' '; return true; } /*数字的识别*/ public Boolean isDigit() throws IOException { if (Character.isDigit(character)) { int value = 0; while (Character.isDigit(character)) { value = 10 * value + Character.digit(character, 10); readch(); } Num n = new Num(value); n.line = line; tokens.add(n); return true; } else return false; } /*保留字、标识符的识别*/ public Boolean isLetter() throws IOException { if (Character.isLetter(character)) { StringBuffer sb = new StringBuffer(); /*首先得到整个的一个分割*/ while (Character.isLetterOrDigit(character)) { sb.append(character); readch(); } /*判断是保留字还是标识符*/ String s = sb.toString(); KeyWord w = keywords.get(s); /*如果是保留字的话,w不应该是空的*/ if (w != null) { w.line = line; tokens.add(w); } else { /*否则就是标识符,此处多出记录标识符编号的语句*/ Symbol sy = new Symbol(s); Symbol mark = sy; //用于标记已存在标识符 Boolean isRepeat = false; sy.line = line; for (Symbol i : symtable) { if (sy.toString().equals(i.toString())) { mark = i; isRepeat = true; } } if (!isRepeat) { sy.pos = symtable.size() + 1; symtable.add(sy); } else if (isRepeat) { sy.pos = mark.pos; } tokens.add(sy); } return true; } else return false; } /*符号的识别*/ public Boolean isSign() throws IOException { switch (character) { case '#': readch(); AllEnd.allEnd.line = line; tokens.add(AllEnd.allEnd); return true; case '/r': if (readch('/n')) { readch(); LineEnd.lineEnd.line = line; tokens.add(LineEnd.lineEnd); line++; return true; } case '(': readch(); Delimiter.lpar.line = line; tokens.add(Delimiter.lpar); return true; case ')': readch(); Delimiter.rpar.line = line; tokens.add(Delimiter.rpar); return true; case ';': readch(); Delimiter.sem.line = line; tokens.add(Delimiter.sem); return true; case '+': readch(); CalcWord.add.line = line; tokens.add(CalcWord.add); return true; case '-': readch(); CalcWord.sub.line = line; tokens.add(CalcWord.sub); return true; case '*': readch(); CalcWord.mul.line = line; tokens.add(CalcWord.mul); return true; case '/': readch(); CalcWord.div.line = line; tokens.add(CalcWord.div); return true; case ':': if (readch('=')) { readch(); CalcWord.assign.line = line; tokens.add(CalcWord.assign); return true; } break; case '>': if (readch('=')) { readch(); CalcWord.ge.line = line; tokens.add(CalcWord.ge); return true; } break; case '<': if (readch('=')) { readch(); CalcWord.le.line = line; tokens.add(CalcWord.le); return true; } break; case '!': if (readch('=')) { readch(); CalcWord.ne.line = line; tokens.add(CalcWord.ne); return true; } break; } return false; } /*下面开始分割关键字,标识符等信息*/ public Token scan() throws IOException { Token tok; while (character == ' ') readch(); if (isDigit() || isSign() || isLetter()) { tok = tokens.get(tokens.size() - 1); } else { tok = new Token(character); printError(tok); } return tok; }}package Yue.LexicalAnalyzer;/* * Token父类 */public class Token { public final int tag; public int line = 1; public String name = ""; public int pos = 0; public Token(int t) { this.tag = t; } public String toString() { return "" + (char) tag; }}package Yue.LexicalAnalyzer;/* * 单词类别赋值 */public class Tag { public final static int BEGIN = 1, //保留字 END = 2, //保留字 INTEGER = 3, //保留字 FUNCTION = 4, //保留字 READ = 5, //保留字 WRITE = 6, //保留字 IF = 7, //保留字 THEN = 8, //保留字 ELSE = 9, //保留字 SYMBOL = 11, //标识符 CONSTANT = 12, //常数 ADD = 13, //运算符 "+" SUB = 14, //运算符 "-" MUL = 15, //运算符 "*" DIV = 16, //运算符 "/" LE = 18, //运算符 "<=" GE = 19, //运算符 ">=" NE = 20, //运算符 "!=" ASSIGN = 23, //运算符 ":=" LPAR = 24, //界符 "(" RPAR = 25, //界符 ")" SEM = 26, //界符 ";" LINE_END = 27, //行尾符 ALL_END = 28; //结尾符 "#"}package Yue.LexicalAnalyzer;/** * 保留字 */public class KeyWord extends Token { public String lexme = ""; public KeyWord(String s, int t) { super(t); this.lexme = s; this.name = "保留字"; } public String toString() { return this.lexme; } public static final KeyWord begin = new KeyWord("begin", Tag.BEGIN), end = new KeyWord("end", Tag.END), integer = new KeyWord("integer", Tag.INTEGER), function = new KeyWord("function", Tag.FUNCTION), read = new KeyWord("read", Tag.READ), write = new KeyWord("write", Tag.WRITE), aIf = new KeyWord("if", Tag.IF), aThen = new KeyWord("then", Tag.THEN), aElse = new KeyWord("else", Tag.ELSE);}package Yue.LexicalAnalyzer;/* * 标识符 */public class Symbol extends Token { public String lexme = ""; public Symbol(String s) { super(Tag.SYMBOL); this.lexme = s; this.name = "标识符"; } public String toString() { return this.lexme; }}package Yue.LexicalAnalyzer;/** * 运算符 */public class CalcWord extends Token { public String lexme = ""; public CalcWord(String s, int t) { super(t); this.lexme = s; this.name = "运算符"; } public String toString() { return this.lexme; } public static final CalcWord add = new CalcWord("+", Tag.ADD), sub = new CalcWord("-", Tag.SUB), mul = new CalcWord("*", Tag.MUL), div = new CalcWord("/", Tag.DIV), le = new CalcWord("<=", Tag.LE), ge = new CalcWord(">=", Tag.GE), ne = new CalcWord("!=", Tag.NE), assign = new CalcWord(":=", Tag.ASSIGN);}package Yue.LexicalAnalyzer;/** * 界符 */public class Delimiter extends Token { public String lexme = ""; public Delimiter(String s, int t) { super(t); this.lexme = s; this.name = "界符"; } public String toString() { return this.lexme; } public static final Delimiter lpar = new Delimiter("(", Tag.LPAR), rpar = new Delimiter(")", Tag.RPAR), sem = new Delimiter(";", Tag.SEM);}package Yue.LexicalAnalyzer;/* * 常数 */public class Num extends Token { public final int value; public Num(int v) { super(Tag.CONSTANT); this.value = v; this.name = "常数"; } public String toString() { return "" + value; }}package Yue.LexicalAnalyzer;/** * 行尾符 */public class LineEnd extends Token { public String lexme = ""; public LineEnd(String s) { super(Tag.LINE_END); this.lexme = s; this.name = "行尾符"; } public String toString() { return this.lexme; } public static final LineEnd lineEnd = new LineEnd("/r/n");}package Yue.LexicalAnalyzer;/** * 结尾符 */public class AllEnd extends Token { public String lexme = ""; public AllEnd(String s) { super(Tag.ALL_END); this.lexme = s; this.name = "结尾符"; } public String toString() { return this.lexme; } public static final AllEnd allEnd = new AllEnd("#");}总结
以上就睡这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流。
新闻热点






疑难解答