在R语言中,数据框(Dataframe)是一个非常重要的数据结构,其组织数据的结构与矩阵相似,但是其各列的数据类型可以不相同。一般情况,数据框的每列是一个变量,每行是一个观测样本。
虽然,数据框内不同的列可以是不同的数据模式,但是数据框内每列的长度必须相同。
1、创建数据框
在R语言中,数据框使用data.frame()函数来创建,其格式如下:
data.frame(col1,col2,..., row.name=NULL, check.rows = FALSE,check.names=TRUE,stringsAsFactors = default.stringsAsFactors())
其中,row.name用于指定各行(样本)的名称,默认没有名称,使用从1开始自增的序列来标识每一行;check.rows用于用来检查行的名称和数量是否一致,默认为FALSE;check.names来检查变量(列)的名称是否唯一且符合语法,默认为TRUE;用来描述是否将字符型向量自动转换为因子,默认转换,若不改变的话使用stringsAsFactors = FALSE来指定即可。
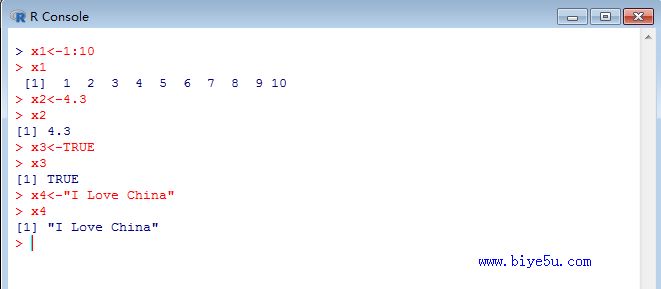
(1)df1<-data.frame(name=c("王宏", "马兰", "刘涛", "张峰"), sex=c("男", "女", "男", "男"), score=c(90, 85, 82, 93))
(2)df2<-data.frame(name=c("王宏", "马兰", "刘涛", "张峰"), sex=c("男", "女", "男", "男"), score=c(90, 85, 82, 93), row.names=c("s1", "s2", "s3", "s4"))
(3)
name <- c("王宏", "马兰", "刘涛", "张峰") #向量
sex <- c("男", "女", "男", "男") #向量
score <- c(90, 85, 82, 93) #向量
df3<-data.frame(name, sex, score) #使用向量生成数据框
以上的执行情况如下图所示,(若图较小,可以点击查看大图)

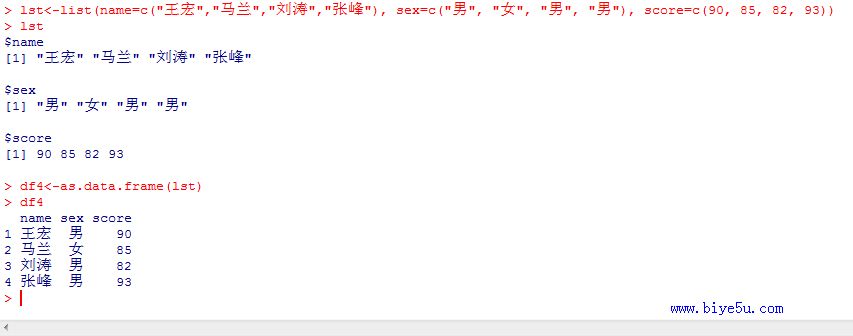
(4)lst<-list(name=c("王宏","马兰","刘涛","张峰"), sex=c("男", "女", "男", "男"), score=c(90, 85, 82, 93))
df4<-as.data.frame(lst)
本部分执行代码如下图所示,(若图较小,请点击看大图)
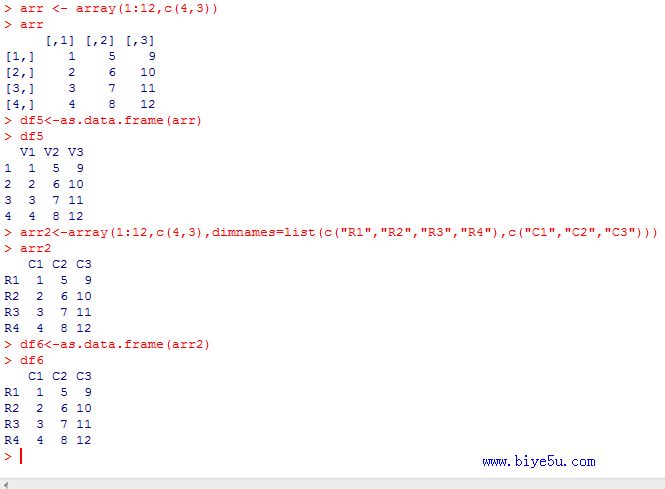
(5)arr1 <- array(1:12,c(4,3))
df5 <- as.data.frame(arr1) #使用数组生成数据框
arr2<- array(1:12, c(4,3),dimnames=list(c("R1","R2","R3","R4"), c("C1","C2","C3")))
df6 <- as.data.frame(arr2)
本部分执行情况如下图所示:
(6) m1 <- matrix(c(1:12),nr=3)
df7<-as.data.frame(m1)
m2<-matrix(c(1:12),nr=3,dimnames=list(c("R1","R2","R3")))
df8<-as.data.frame(m2)
m3<-matrix(c(1:12),nr=3,dimnames=list(c(),c("C1","C2","C3","C4")))
df9<-as.data.frame(m3)
本部分的执行情况如下:
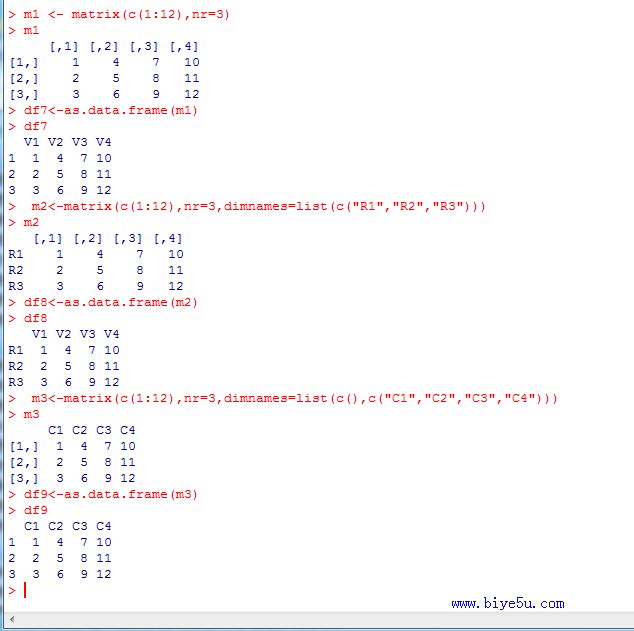
在使用数组,矩阵生成数据框时,若没有指定列名,则以"V1","V2”......进行代替。
2、数据框的引用
(1)df1["score"] #仍为一个数据框, 也是一个列表
(2)df1[,"score"] #返回的是向量
(3)df1[3] #同(1)
(4)df1[,3] #同(2)
(5)df1[c(1,3)] #返回第1列和第3列的数据
以上执行情况如下图所示:

(6)df1[c(1,3),] #返回第1行和第3行的数据
(7)df1[c(1,3),c(2,3)] #返回第1行和第3行与第2列和第3列交叉处的数据
(8)df1$name #以因子的形式返回name列
(9)df1[["name"]] #以因子的形式返回name列
(10)df1[[1]][1] #返回第1分量的第一个元素值,王宏
(11)df1[['name']][1] #返回name分量第一个元素值:王宏
(12)df1$name[1] #返回name分量第一个元素值:王宏
3、数据框的修改
(1)增加样本数据或变量
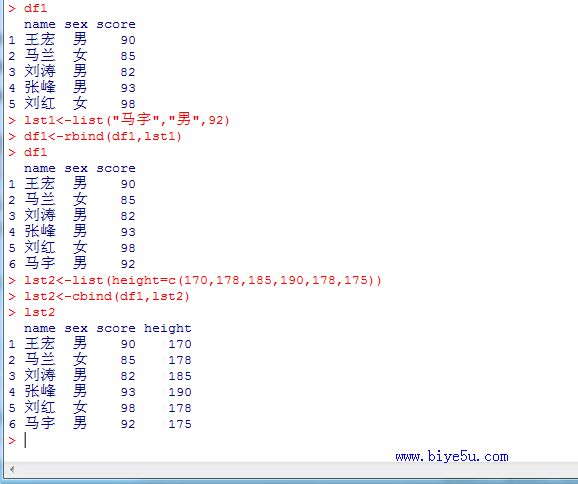
可以使用rbind()函数和cbind()函数将新行或新列添加到数据框变量中。
lst1<-list("马宇","男",92) #创建一个新列表
df1<-rbind(df1,lst1) #将列表lst1添加到df1中
lst2<-list(height=c(170,178,185,190,178,175)) #创建一个新列表,保存身高
df1<-cbind(df1,lst2) #使用cbind将lst2添加到df1中
本部分执行情况如下图所示:
(2)修改某列的某一个值
df1$name[1] <- "王宏伟" #将王宏的值修改为王宏伟
df1[1,2] <- "女" #将第一行第2列的值修改为“女”
df1[[1]][2]<-"马兰兰" #将第一列第二个值改为“马兰兰”
(3)删除行或列
df1<-df1[-2,] #删除第2行数据
df1<-df1[,-4] #删除第4列的数据
df1<-df1[-c(1,3),] #删除第1行和第3行的数据
df1<-df1[,-c(1,4)] #删除第1列和第4列的数据
本部分(完)
新闻热点






疑难解答