首页| 新闻| 娱乐| 游戏| 科普| 文学| 编程| 系统| 数据库| 建站| 学院| 产品| 网管| 维修| 办公| 热点
利用笔记本双网卡(有线和无线)
笔记本通过USB无线网卡共享无
HP520笔记本 无法识别CDMA无线上网卡的解
校园甜美的背影,洋溢着青春烂漫的回忆
芭蕾舞蹈表演,真实美到极致
春天的魅力:绿杨烟外晓寒轻
春节临近,各地春节彩灯高高挂
肉食主义者的最爱美食烤肉图片
夏日甜心草莓美食图片
人逢知己千杯少,喝酒搞笑图集
搞笑试卷,学生恶搞答题
新闻热点
疑难解答
图片精选
建站教程:网站的标题怎么定?
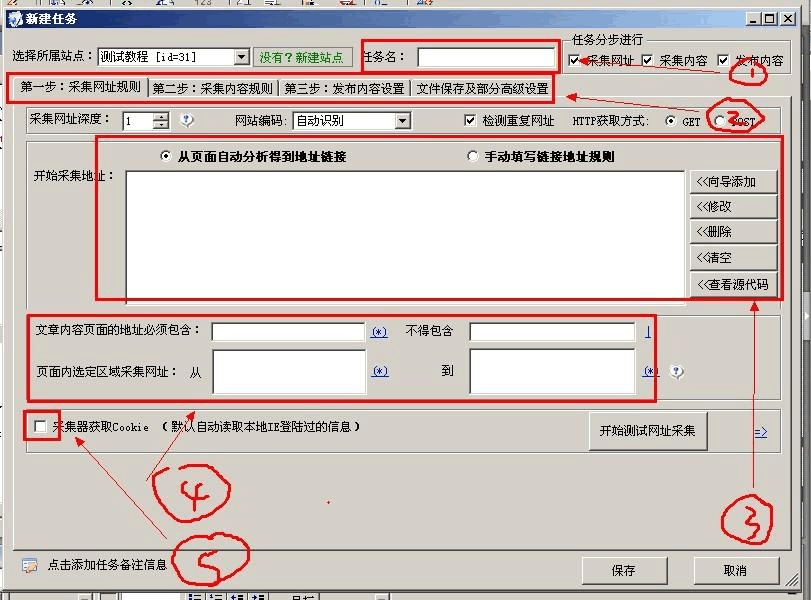
网站如何防采集?怎样防止别人采集网
网站建设和网站运营需要注意什么重
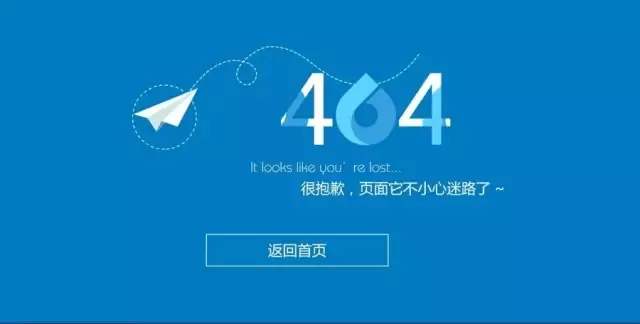
建站教程:网站建设之404页面怎么设
网友关注