上节基本完成了SVM的理论推倒,寻找最大化间隔的目标最终转换成求解拉格朗日乘子变量alpha的求解问题,求出了alpha即可求解出SVM的权重W,有了权重也就有了最大间隔距离,但是其实上节我们有个假设:就是训练集是线性可分的,这样求出的alpha在[0,infinite]。但是如果数据不是线性可分的呢?此时我们就要允许部分的样本可以越过分类器,这样优化的目标函数就可以不变,只要引入松弛变量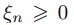 即可,它表示错分类样本点的代价,分类正确时它等于0,当分类错误时
即可,它表示错分类样本点的代价,分类正确时它等于0,当分类错误时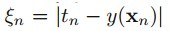 ,其中Tn表示样本的真实标签-1或者1,回顾上节中,我们把支持向量到分类器的距离固定为1,因此两类的支持向量间的距离肯定大于1的,当分类错误时
,其中Tn表示样本的真实标签-1或者1,回顾上节中,我们把支持向量到分类器的距离固定为1,因此两类的支持向量间的距离肯定大于1的,当分类错误时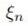 肯定也大于1,如(图五)所示(这里公式和图标序号都接上一节)。
肯定也大于1,如(图五)所示(这里公式和图标序号都接上一节)。
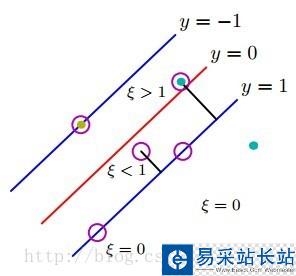
(图五)
这样有了错分类的代价,我们把上节(公式四)的目标函数上添加上这一项错分类代价,得到如(公式八)的形式:

(公式八)
重复上节的拉格朗日乘子法步骤,得到(公式九):
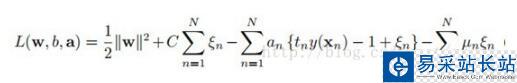
(公式九)
多了一个Un乘子,当然我们的工作就是继续求解此目标函数,继续重复上节的步骤,求导得到(公式十):

(公式十)
又因为alpha大于0,而且Un大于0,所以0<alpha<C,为了解释的清晰一些,我们把(公式九)的KKT条件也发出来(上节中的第三类优化问题),注意Un是大于等于0:

推导到现在,优化函数的形式基本没变,只是多了一项错分类的价值,但是多了一个条件,0<alpha<C,C是一个常数,它的作用就是在允许有错误分类的情况下,控制最大化间距,它太大了会导致过拟合,太小了会导致欠拟合。接下来的步骤貌似大家都应该知道了,多了一个C常量的限制条件,然后继续用SMO算法优化求解二次规划,但是我想继续把核函数也一次说了,如果样本线性不可分,引入核函数后,把样本映射到高维空间就可以线性可分,如(图六)所示的线性不可分的样本:
新闻热点




疑难解答