项目地址:https://github.com/jrainlau/wallpaper-downloader
前言
好久没有写文章了,因为最近都在适应新的岗位,以及利用闲暇时间学习python。这篇文章是最近的一个python学习阶段性总结,开发了一个爬虫批量下载某壁纸网站的高清壁纸。
注意:本文所属项目仅用于python学习,严禁作为其他用途使用!
初始化项目
项目使用了virtualenv来创建一个虚拟环境,避免污染全局。使用pip3直接下载即可:
pip3 install virtualenv
然后在合适的地方新建一个wallpaper-downloader目录,使用virtualenv创建名为venv的虚拟环境:
virtualenv venv. venv/bin/activate
接下来创建依赖目录:
echo bs4 lxml requests > requirements.txt
最后yun下载安装依赖即可:
pip3 install -r requirements.txt
分析爬虫工作步骤
为了简单起见,我们直接进入分类为“aero”的壁纸列表页:http://wallpaperswide.com/aer...。
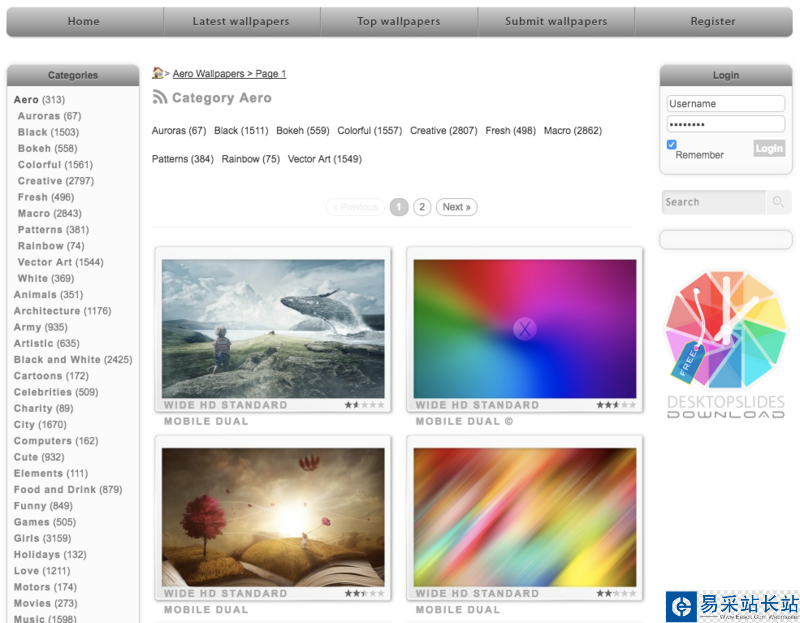
可以看到,这一页里面一共有10张可供下载的壁纸。但是由于这里显示的都是缩略图,作为壁纸来说清晰度是远远不够的,所以我们需要进入壁纸详情页,去找到高清的下载链接。从第一张壁纸点进去,可以看到一个新的页面:
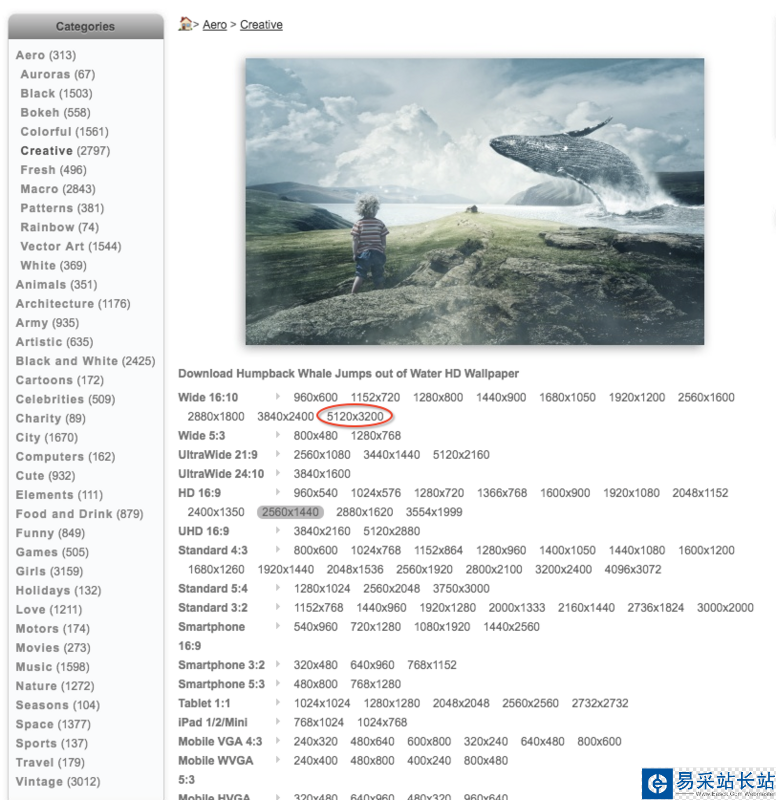
因为我机器是Retina屏幕,所以我打算直接下载体积最大的那个以保证高清(红圈所示体积)。
了解了具体的步骤以后,就是通过开发者工具找到对应的dom节点,提取相应的url即可,这个过程就不再展开了,读者自行尝试即可,下面进入编码部分。
访问页面
新建一个download.py文件,然后引入两个库:
from bs4 import BeautifulSoupimport requests
接下来,编写一个专门用于访问url,然后返回页面html的函数:
def visit_page(url): headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36' } r = requests.get(url, headers = headers) r.encoding = 'utf-8' soup = BeautifulSoup(r.text, 'lxml') return soup为了防止被网站反爬机制击中,所以我们需要通过在header添加UA把爬虫伪装成正常的浏览器,然后指定utf-8编码,最后返回字符串格式的html。
提取链接
在获取了页面的html以后,就需要提取这个页面壁纸列表所对应的url了:
def get_paper_link(page): links = page.select('#content > div > ul > li > div > div a') collect = [] for link in links: collect.append(link.get('href')) return collect
新闻热点




疑难解答