研究了一段时间酷狗音乐的接口,完美破解了其vip音乐下载方式,想着能更好的追求开源,故写下此篇文章,本文仅供学习参考。虽然没什么技术含量,但都是自己一点一点码出来,一点一点抓出来的。
一、综述:
根据酷狗的搜索接口以及无损音乐下载接口,做出爬虫系统。采用flask框架,前端提取搜索关键字,后端调用爬虫系统采集数据,并将数据前端呈现;
运行环境:windows/linux python2.7
二、爬虫开发:
通过抓包的方式对酷狗客户端进行抓包,抓到两个接口:
1、搜索接口:
http://songsearch.kugou.com/song_search_v2?keyword={关键字}page=1
这个接口通过传递关键字,其返回的是一段json数据,数据包含音乐名称、歌手、专辑、总数据量等信息,当然最重要的是数据包含音乐各个品质的hash。
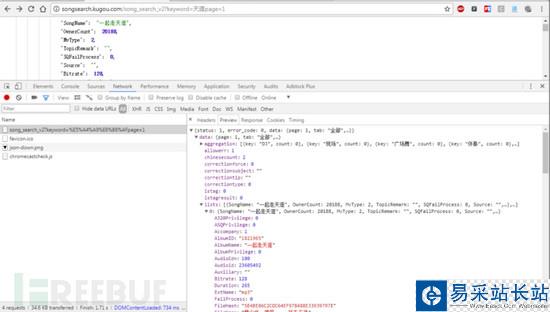
默认接口返回的数据只包含30首音乐,为了能拿到所有的数据,只需要把pagesize更改就可以,所以我提取了总数据数量,然后再次发动一次数据请求,拿到全部的数据。当然,这个总数据量也就是json中的total也是作为搜索结果的依据,如果total == 0 则判断无法搜索到数据。
搜索到数据后,我就要提取无损音乐的hash,这个hash是音乐下载的关键,无损音乐hash键名:SQFileHash,提取到无损hash(如果是32个0就表示None),我把他的名称、歌手、hash以字典形式传递给下一个模块。
代码实现:
a.请求模块(复用率高):
# coding=utf-8import requestsimport jsonheaders = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cache-Control': 'max-age=0', 'Connection': 'keep-alive', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/63.0.3239.132 Safari/537.36',}def parse(url): ret = json.loads(requests.get(url, headers=headers, timeout=5).text) # 返回的是已经转换过后的字典数据 return retif __name__ == '__main__': parse()b.搜索模块
# coding=utf-8import copyimport MusicParsedef search(keyword): search_url = 'http://songsearch.kugou.com/song_search_v2?keyword={}page=1'.format(keyword) # 这里需要判断一下,ip与搜索字段可能会限制搜索,total进行判断 total = MusicParse.parse(search_url)['data']['total'] if total != 0: search_total_url = search_url + '&pagesize=%d' % total music_list = MusicParse.parse(search_total_url)['data']['lists'] item, items = {}, [] for music in music_list: if music['SQFileHash'] != '0'*32: item['Song'] = music['SongName'] # 歌名 item['Singer'] = music['SingerName'] # 歌手 item['Hash'] = music['SQFileHash'] # 歌曲无损hash items.append(copy.deepcopy(item)) return items else: return Noneif __name__ == '__main__': search()
新闻热点




疑难解答