本文主要内容:
聚类算法的特点 聚类算法样本间的属性(包括,有序属性、无序属性)度量标准 聚类的常见算法,原型聚类(主要论述K均值聚类),层次聚类、密度聚类 K均值聚类算法的python实现,以及聚类算法与EM最大算法的关系 参考引用先上一张gif的k均值聚类算法动态图片,让大家对算法有个感性认识:
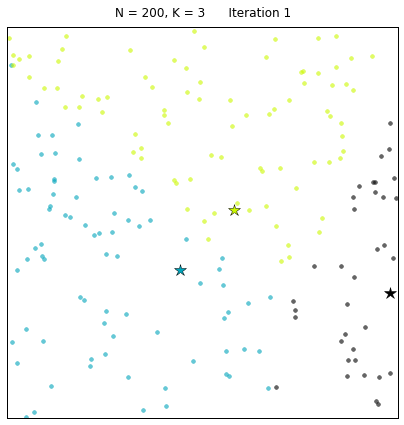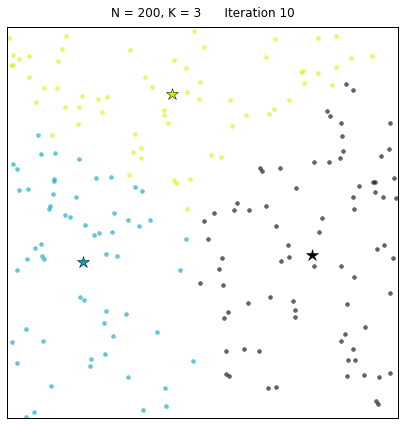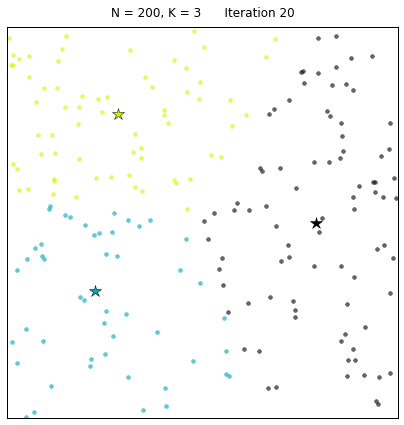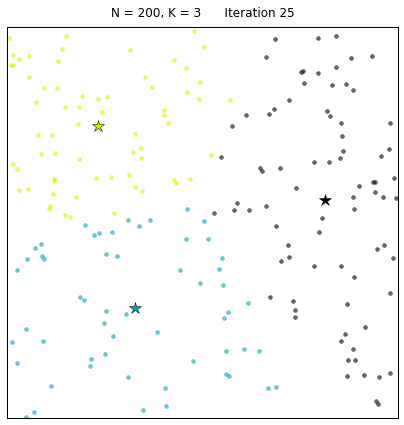
其中:N=200代表有200个样本,不同的颜色代表不同的簇(其中 3种颜色为3个簇),星星代表每个簇的簇心。算法通过25次迭代找到收敛的簇心,以及对应的簇。 每次迭代的过程中,簇心和对应的簇都在变化。
聚类算法的特点
聚类算法是无监督学习算法和前面的有监督算法不同,训练数据集可以不指定类别(也可以指定)。聚类算法对象归到同一簇中,类似全自动分类。簇内的对象越相似,聚类的效果越好。K-均值聚类是每个类别簇都是采用簇中所含值的均值计算而成。

聚类样本间的属性(包括,有序属性、无序属性)度量标准 1. 有序属性
例如:西瓜的甜度:0.1, 0.5, 0.9(值越大,代表越甜)
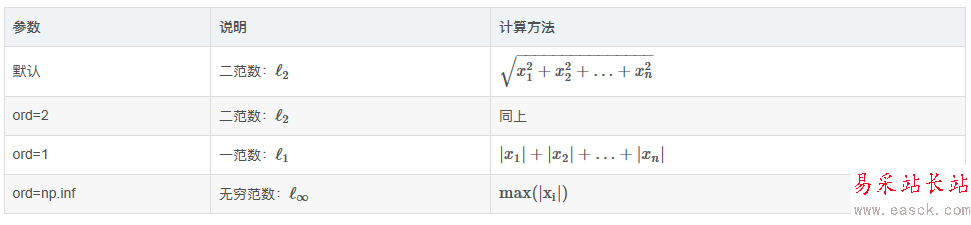
我们可以使用明可夫斯基距离定义:

2. 无序属性
例如:色泽,青绿、浅绿、深绿(又例如: 性别: 男, 女, 中性,人yao…明显也不能使用0.1, 0.2 等表示求距离)。这些不能使用连续的值表示,求距离的,一般使用VDM计算:


聚类的常见算法,原型聚类(主要论述K均值聚类),层次聚类、密度聚类
聚类算法分为如下三大类:
1. 原型聚类(包含3个子类算法):
K均值聚类算法
学习向量量化
高斯混合聚类
2. 密度聚类:
3. 层次聚类:
下面主要说明K均值聚类算法(示例来源于,周志华西瓜书)
算法基本思想:
K-Means 是发现给定数据集的 K 个簇的聚类算法, 之所以称之为 K-均值 是因为它可以发现 K 个不同的簇,且每个簇的中心采用簇中所含值的均值计算而成.簇个数 K 是用户指定的, 每一个簇通过其质心(centroid), 即簇中所有点的中心来描述.
算法流程如下:

主要是三个步骤:
初始化选择K个簇心,假设样本有 m个属性,则相当于k个m为向量 对于k个簇,求离其最近的样本,并划分新的簇 对于每个新的簇,更新簇心的向量(一般可以求簇的样本的属性的均值) 重复2~3直到算法收敛,或者运行了指定的次数新闻热点



疑难解答