本文介绍了python opencv之SIFT算法示例,分享给大家,具体如下:
目标:
学习SIFT算法的概念
学习在图像中查找SIFT关键的和描述符
原理:
(原理部分自己找了不少文章,内容中有不少自己理解和整理的东西,为了方便快速理解内容和能够快速理解原理,本文尽量不使用数学公式,仅仅使用文字来描述。本文中有很多引用别人文章的内容,仅供个人记录使用,若有错误,请指正出来,万分感谢)
之前的harris算法和Shi-Tomasi 算法,由于算法原理所致,具有旋转不变性,在目标图片发生旋转时依然能够获得相同的角点。但是如果对图像进行缩放以后,再使用之前的算法就会检测不出来,原理用一张图表示(图1):
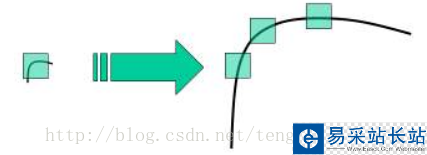
(harris算法和shi-tomasi算法都是基于窗口中像素分布和变化的原理,在图像放大且窗口大小不发生变化的时,窗口中的像素信息则会有很大的不同,造成无法检测的结果)
SIFT特性:
SIFT特点:
SIFT算法步骤:
尺度空间极值检测:
尺度空间的个人理解:
你找一张分辨率1024×1024图片,在电脑上观看,十分清晰,但是图片太大。现在把这图片反正photoshop上,将分辨率改成512×512,图片看着依然很清晰,但是不可能像1024×1024的画面那么精细,只不过是因为人眼构造的原因,512×512图片依然能让你分辨出这是个什么东西。
粗俗点说,尺度空间,就相当于一个图片需要获得多少分辨率的量级。如果把一个图片从原始分辨率到,不停的对其分辨率进行减少,然后将这些图片摞在一起,可以看成一个四棱锥的样式,这个东西就叫做图像金字塔(如下图,图2)。
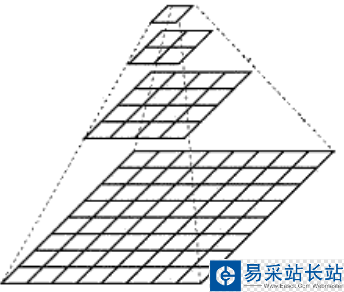
再回到尺度空间,在摄像头中,计算机无法分辨一个景物的尺度信息。而人眼不同,除了人大脑里已经对物体有了基本的概念(例如正常人在十几米外看到苹果,和在近距离看到苹果,都能认出是苹果)以外,人眼在距离物体近时,能够获得物体足够多的特性,在距离物体远时,能够或略细节,例如,近距离看一个人脸能看到毛孔,距离远了看不到毛孔等等。
新闻热点



疑难解答