前面文章分别简单介绍了线性回归,逻辑回归,贝叶斯分类,并且用python简单实现。这篇文章介绍更简单的 knn, k-近邻算法(kNN,k-NearestNeighbor)。
k-近邻算法(kNN,k-NearestNeighbor),是最简单的机器学习分类算法之一,其核心思想在于用距离目标最近的k个样本数据的分类来代表目标的分类(这k个样本数据和目标数据最为相似)。
原理
kNN算法的核心思想是用距离最近(多种衡量距离的方式)的k个样本数据来代表目标数据的分类。
具体讲,存在训练样本集, 每个样本都包含数据特征和所属分类值。
输入新的数据,将该数据和训练样本集汇中每一个样本比较,找到距离最近的k个,在k个数据中,出现次数做多的那个分类,即可作为新数据的分类。
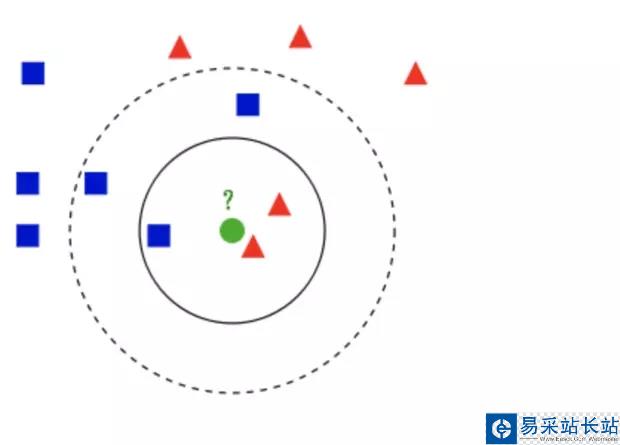
如上图:
需要判断绿色是什么形状。当k等于3时,属于三角。当k等于5是,属于方形。
因此该方法具有一下特点:
接下来用oython 做个简单实现, 并且尝试用于约会网站配对。
python简单实现
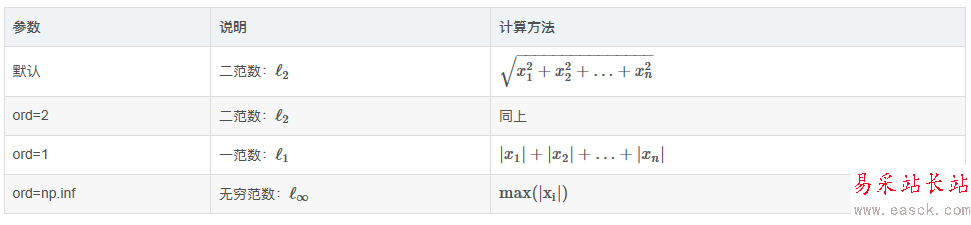
def classify(inX, dataSet, labels, k): """ 定义knn算法分类器函数 :param inX: 测试数据 :param dataSet: 训练数据 :param labels: 分类类别 :param k: k值 :return: 所属分类 """ dataSetSize = dataSet.shape[0] #shape(m, n)m列n个特征 diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet sqDiffMat = diffMat ** 2 sqDistances = sqDiffMat.sum(axis=1) distances = sqDistances ** 0.5 #欧式距离 sortedDistIndicies = distances.argsort() #排序并返回index classCount = {} for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 #default 0 sortedClassCount = sorted(classCount.items(), key=lambda d:d[1], reverse=True) return sortedClassCount[0][0]算法的步骤上面有详细的介绍,上面的计算是矩阵运算,下面一个函数是代数运算,做个比较理解。
def classify_two(inX, dataSet, labels, k): m, n = dataSet.shape # shape(m, n)m列n个特征 # 计算测试数据到每个点的欧式距离 distances = [] for i in range(m): sum = 0 for j in range(n): sum += (inX[j] - dataSet[i][j]) ** 2 distances.append(sum ** 0.5) sortDist = sorted(distances) # k 个最近的值所属的类别 classCount = {} for i in range(k): voteLabel = labels[ distances.index(sortDist[i])] classCount[voteLabel] = classCount.get(voteLabel, 0) + 1 # 0:map default sortedClass = sorted(classCount.items(), key=lambda d:d[1], reverse=True) return sortedClass[0][0]
新闻热点



疑难解答