我们都见识过requests库在静态网页的爬取上展现的威力,我们日常见得最多的为get和post请求,他们最大的区别在于安全性上:
1、GET是通过URL方式请求,可以直接看到,明文传输。
2、POST是通过请求header请求,可以开发者工具或者抓包可以看到,同样也是明文的。 3.GET请求会保存在浏览器历史纪录中,还可能会保存在Web的日志中。
两者用法上也有显著差异(援引自知乎):
1、GET用于从服务器端获取数据,包括静态资源(HTML|JS|CSS|Image等等)、动态数据展示(列表数据、详情数据等等)。
2、POST用于向服务器提交数据,比如增删改数据,提交一个表单新建一个用户、或修改一个用户等。
对于Post请求,我们可以通过浏览器开发者工具或者其他外部工具来进行抓包,得到请求的URL、请求头(request headers)以及请求的表单data信息,这三样恰恰是我们用requests模拟post请求时需要的,典型的写法如下:
response=requests.post(url=url,headers=headers,data=data_search)
由于post请求很多时候是配合Ajax(异步加载)技术一起使用的,我们抓包时,可以直接选择XHR(XmlHttpRequest)-ajax的一种对象,帮助我们滤掉其他的一些html、css、js类文件,如下图所示(截取自Chrome):
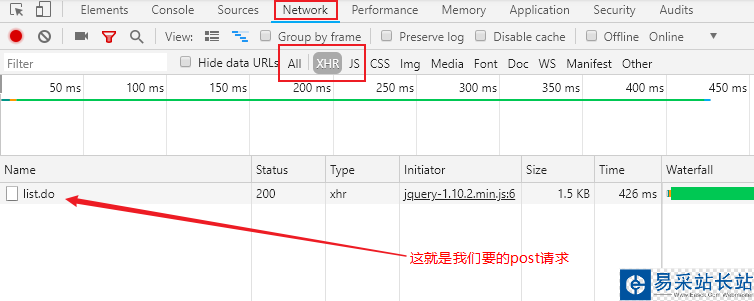
双击点开,就可以在页面右边的Headers页下看到General、Response Headers、Request Headers、Form Data几个模块,
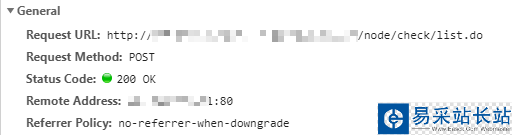
其中General模块能看到请求的方法和请求的URL以及服务器返回的状态码(200(成功) 服务器已成功处理了请求。通常,这表示服务器提供了请求的网页。)
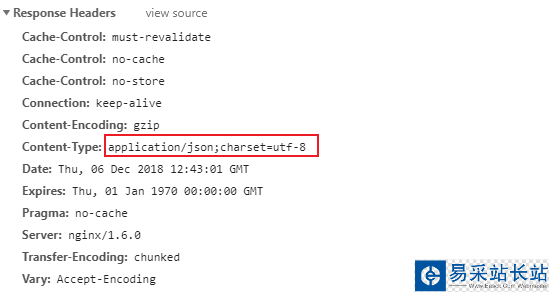
而Response Headers部分,可以看到缓存控制、服务器类型、返回内容格式、有效期等参数(笔者截图所示,返回的为json文件):
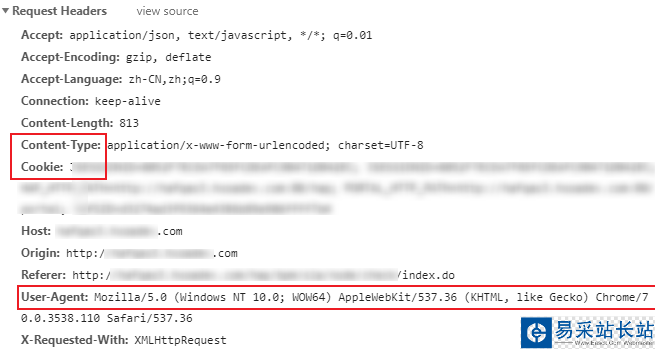
Request Header模块是非常重要的,可以有效地将我们的爬取行为模拟成浏览器行为,应对常规的服务器反爬机制:
其中Content-Type、Cookie以及User-Agent字段较为重要,需要我们构造出来(其他字段大多数时候,不是必须)
由于Cookie字段记录了用户的登陆信息,每次都不同,且同一个cookie存在一定有效期,当我们结合Selenium来组合爬取页面信息时,可以通过selenium完成网页的登陆校验,然后利用selenium提取出cookie,再转换为浏览器能识别的cookie格式,通常代码如下所示:
cookies = driver.get_cookies() #利用selenium原生方法得到cookiesret=''for cookie in cookies: cookie_name=cookie['name'] cookie_value=cookie['value'] ret=ret+cookie_name+'='+cookie_value+';' #ret即为最终的cookie,各cookie以“;”相隔开
新闻热点






疑难解答













