扫描器需要实现的功能思维导图
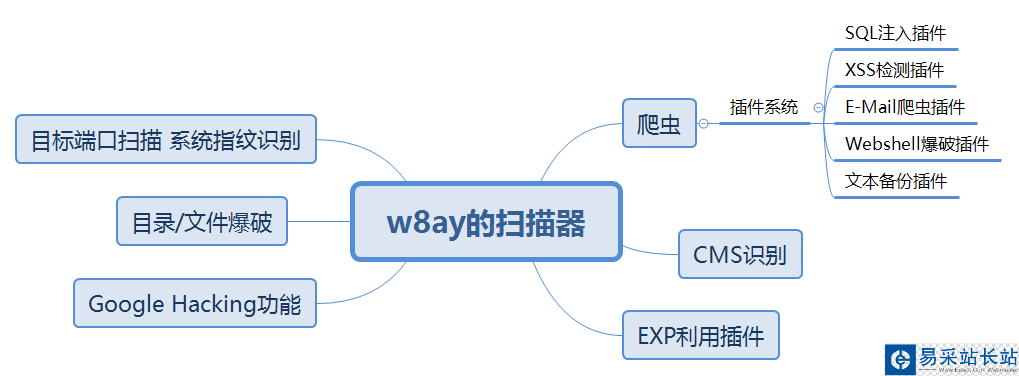
爬虫编写思路
首先需要开发一个爬虫用于收集网站的链接,爬虫需要记录已经爬取的链接和待爬取的链接,并且去重,用 Python 的set()就可以解决,大概流程是:
输入 URL 下载解析出 URL URL 去重,判断是否为本站 加入到待爬列表 重复循环SQL 判断思路
通过在 URL 后面加上AND %d=%d或者OR NOT (%d>%d) %d后面的数字是随机可变的 然后搜索网页中特殊关键词,比如:MySQL 中是 SQL syntax.*MySQL
Microsoft SQL Server 是 Warning.*mssql_
Microsoft Access 是 Microsoft Access Driver
Oracle 是 Oracle error
IBM DB2 是 DB2 SQL error
SQLite 是 SQLite.Exception
...
通过这些关键词就可以判断出所用的数据库
请安装这些库
pip install requestspip install beautifulsoup4
实验环境是 Linux,创建一个Code目录,在其中创建一个work文件夹,将其作为工作目录
目录结构
/w8ay.py // 项目启动主文件
/lib/core // 核心文件存放目录
/lib/core/config.py // 配置文件
/script // 插件存放
/exp // exp和poc存放
步骤
SQL 检测脚本编写
DBMS_ERRORS = { 'MySQL': (r"SQL syntax.*MySQL", r"Warning.*mysql_.*", r"valid MySQL result", r"MySqlClient/."), "PostgreSQL": (r"PostgreSQL.*ERROR", r"Warning.*/Wpg_.*", r"valid PostgreSQL result", r"Npgsql/."), "Microsoft SQL Server": (r"Driver.* SQL[/-/_/ ]*Server", r"OLE DB.* SQL Server", r"(/W|/A)SQL Server.*Driver", r"Warning.*mssql_.*", r"(/W|/A)SQL Server.*[0-9a-fA-F]{8}", r"(?s)Exception.*/WSystem/.Data/.SqlClient/.", r"(?s)Exception.*/WRoadhouse/.Cms/."), "Microsoft Access": (r"Microsoft Access Driver", r"JET Database Engine", r"Access Database Engine"), "Oracle": (r"/bORA-[0-9][0-9][0-9][0-9]", r"Oracle error", r"Oracle.*Driver", r"Warning.*/Woci_.*", r"Warning.*/Wora_.*"), "IBM DB2": (r"CLI Driver.*DB2", r"DB2 SQL error", r"/bdb2_/w+/("), "SQLite": (r"SQLite/JDBCDriver", r"SQLite.Exception", r"System.Data.SQLite.SQLiteException", r"Warning.*sqlite_.*", r"Warning.*SQLite3::", r"/[SQLITE_ERROR/]"), "Sybase": (r"(?i)Warning.*sybase.*", r"Sybase message", r"Sybase.*Server message.*"),}通过正则表达式就可以判断出是哪个数据库了
新闻热点






疑难解答













