__import__函数
我们都知道import是导入模块的,但是其实import实际上是使用builtin函数import来工作的。在一些程序中,我们可以动态去调用函数,如果我们知道模块的名称(字符串)的时候,我们可以很方便的使用动态调用
def getfunctionbyname(module_name, function_name): module = __import__(module_name) return getattr(module, function_name)
通过这段代码,我们就可以简单调用一个模块的函数了
插件系统开发流程
一个插件系统运转工作,主要进行以下几个方面的操作
获取插件,通过对一个目录里的.py文件扫描得到 将插件目录加入到环境变量sys.path 爬虫将扫描好的 URL 和网页源码传递给插件 插件工作,工作完毕后将主动权还给扫描器插件系统代码
在lib/core/plugin.py中创建一个spiderplus类,实现满足我们要求的代码
# __author__ = 'mathor'import osimport sysclass spiderplus(object): def __init__(self, plugin, disallow = []): self.dir_exploit = [] self.disallow = ['__init__'] self.disallow.extend(disallow) self.plugin = os.getcwd() + '/' + plugin sys.path.append(plugin) def list_plusg(self): def filter_func(file): if not file.endswith('.py'): return False for disfile in self.disallow: if disfile in file: return False return True dir_exploit = filter(filter_func, os.listdir(self.plugin) return list(dir_exploit) def work(self, url, html): for _plugin in self.list_plusg(): try: m = __import__(_plugin.split('.')[0]) spider = getattr(m, 'spider') p = spider() s = p.run(url, html) except Exception as e: print (e)work函数中需要传递 url,html,这个就是我们扫描器传给插件系统的,通过代码
spider = getattr(m, 'spider')p = spider()s = p.run(url, html)
我们定义插件必须使用class spider中的run方法调用
扫描器中调用插件
我们主要用爬虫调用插件,因为插件需要传递 url 和网页源码这两个参数,所以我们在爬虫获取到这两个的地方加入插件系统代码即可
首先打开Spider.py,在Spider.py文件开头加上
from lib.core import plugin
然后在文件的末尾加上
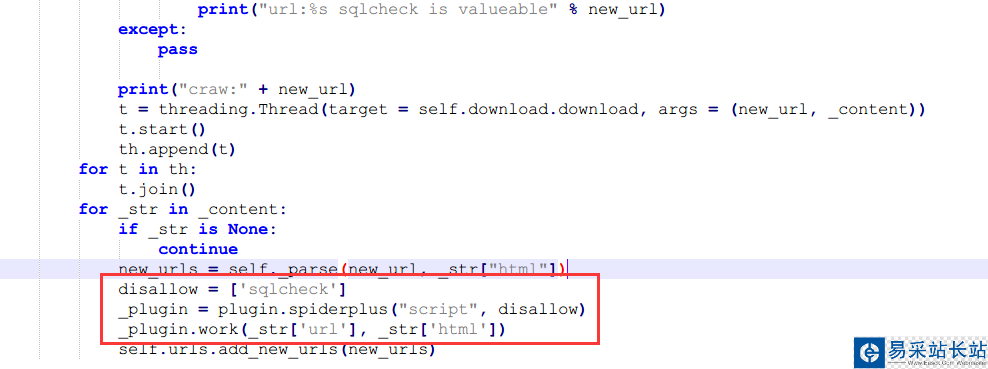
disallow = ['sqlcheck']_plugin = plugin.spiderplus('script', disallow)_plugin.work(_str['url'], _str['html'])disallow是不允许的插件列表,为了方便测试,我们可以把 sqlcheck 填上
SQL 注入融入插件系统
其实非常简单,只需要修改script/sqlcheck.py为下面即可
关于Download模块,其实就是Downloader模块,把Downloader.py复制一份命名为Download.py就行
新闻热点






疑难解答













