本文主要给大家介绍的是关于python爬取散文网文章的相关内容,分享出来供大家参考学习,下面一起来看看详细的介绍:
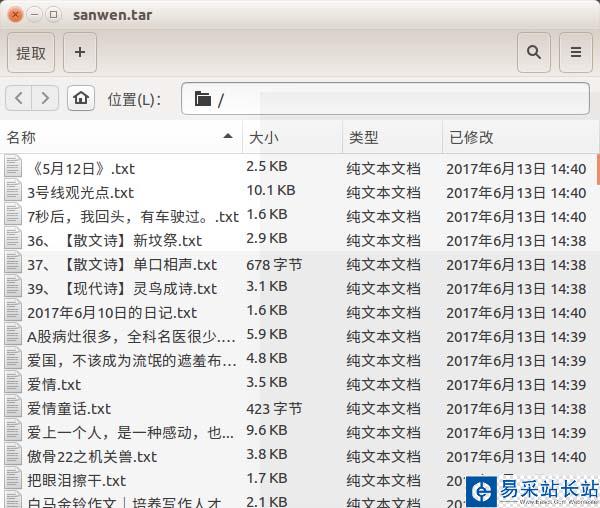
效果图如下:
配置python 2.7
bs4 requests
安装 用pip进行安装 sudo pip install bs4
sudo pip install requests
简要说明一下bs4的使用因为是爬取网页 所以就介绍find 跟find_all
find跟find_all的不同在于返回的东西不同 find返回的是匹配到的第一个标签及标签里的内容
find_all返回的是一个列表
比如我们写一个test.html 用来测试find跟find_all的区别。
内容是:
<html><head></head><body><div id="one"><a></a></div><div id="two"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >abc</a></div><div id="three"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a></div><div id="four"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >four<p>four p</p><p>four p</p><p>four p</p> a</a></div></body></html>
然后test.py的代码为:
from bs4 import BeautifulSoupimport lxmlif __name__=='__main__': s = BeautifulSoup(open('test.html'),'lxml') print s.prettify() print "------------------------------" print s.find('div') print s.find_all('div') print "------------------------------" print s.find('div',id='one') print s.find_all('div',id='one') print "------------------------------" print s.find('div',id="two") print s.find_all('div',id="two") print "------------------------------" print s.find('div',id="three") print s.find_all('div',id="three") print "------------------------------" print s.find('div',id="four") print s.find_all('div',id="four") print "------------------------------"运行以后我们可以看到结果当获取指定标签时候两者区别不大当获取一组标签的时候两者的区别就会显示出来
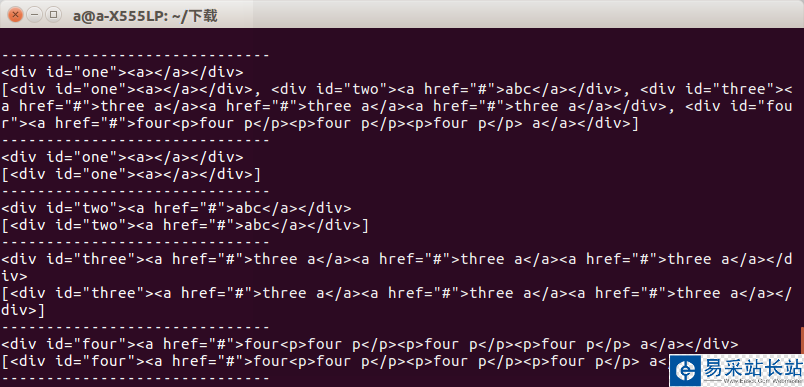
所以我们在使用时候要注意到底要的是什么,否则会出现报错
新闻热点






疑难解答













