前言
Django数据层提供各种途径优化数据的访问,一个项目大量优化工作一般是放在后期来做,早期的优化是“万恶之源”,这是前人总结的经验,不无道理。如果事先理解Django的优化技巧,开发过程中稍稍留意,后期会省不少的工作量。
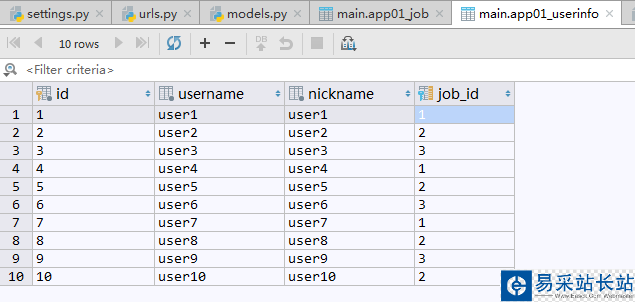
现在有一张记录用户信息的UserInfo数据表,表中记录了10个用户的姓名,呢称,年龄,工作等信息.
models文件
from django.db import models class Job(models.Model): title=models.CharField(max_length=32) class UserInfo(models.Model): username=models.CharField(max_length=32) nickname=models.CharField(max_length=32) job=models.ForeignKey(to="Job",to_field="id",null=True)
数据表中记录:
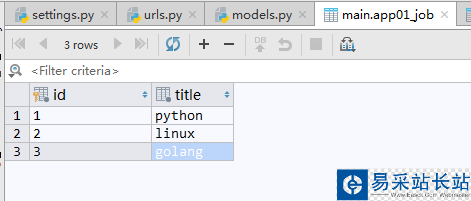
另一张数据表记录用户工作的Job表,关联用户的工作字段.
要查出每个用户的用户名,呢称和工作等信息
def index(request): user_list=models.UserInfo.objects.all() print(user_list.query) # 打印查询时使用的语句 print(type(user_list)) # 打印查询结果的数据类型 for user in user_list: print("%s-->%s-->%s" %(user.username,user.nickname,user.job.title)) return render(request,'index.html')打印信息:
SELECT "app01_userinfo"."id", "app01_userinfo"."username", "app01_userinfo"."nickname", "app01_userinfo"."job_id" FROM "app01_userinfo"<class 'django.db.models.query.QuerySet'>user1-->user1-->pythonuser2-->user2-->linuxuser3-->user3-->golanguser4-->user4-->pythonuser5-->user5-->linuxuser6-->user6-->golanguser7-->user7-->pythonuser8-->user8-->linuxuser9-->user9-->golanguser10-->user10-->linux
在服务端进行这些操作,这些查询语句的性能是很低的,遍历取出这10个用户的姓名,呢称,工作等信息要在两张数据库中执行11次查询操作.
首先只从UserInfo表中查出所有的用户记录,需要执行一次查询操作.
查询Job数据表,每循环一次用户信息的列表,都需要从Job表中查询一次用户的工作信息.
数据表中总共记录了10条用户记录,所以还需要循环10次才能从Job表中查询完成所有用户的工作信息.所以一共需要执行11次数据库查询操作.
那有没有什么好的方法能够提高数据库查询的效率呢???
def index(request): user_list=models.UserInfo.objects.values("username","nickname","job") print(user_list.query) # 打印查询时使用的语句 print(type(user_list)) # 打印查询结果的数据类型 print("user_list:",user_list) for user in user_list: print(user["username"], user["nickname"], user["job"]) return render(request,'index.html')
新闻热点






疑难解答













