一、Python2中的字符存在的解码编码问题
如果是现在正在用Python2的人应该都知道存在字符编码问题,就举一个最简单的例子吧:Python2是无法在命令行直接打印中文的,当然他也是不会报错的,顶多是一堆你看不懂的乱码。如果想在直接显示中文,我们是可以在Python2文件头部申明字符编码的格式。如下图
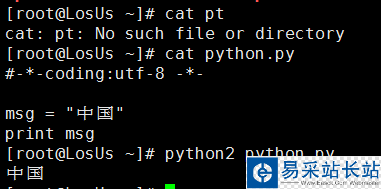
这里 #-*-coding:utf-8 -*- 是用来申明下面的代码是用什么编码来解释;
1.1.Python2中的解码和编码:
在编码和解码的世界中,我们得需要找一个大家都知道的文字。也可以这么理解。我是一个中国人现在和一个日本人沟通,我肯定是无法理解他说的是什么,他同样也无法理解,但是这样就没有办法了吗?或许我们需要一个国际的语言——英语。这样来自不同国家的人也可以进行沟通了(虽然我知道 are you ok 0-0)。在编码中也是一样,gbk和utf-8都不知道对方的格式是什么吊意思。所以如果要上gbk读懂utf-8的编码就得将utf-8 decode成 Unicode,而Unicode有知道gkb,这里需要将Unicode在encode成gbk就行了
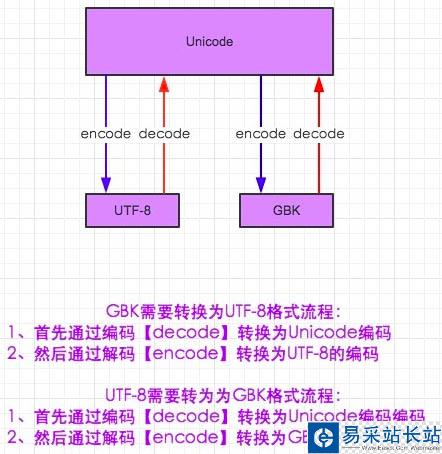
#-*- coding:utf-8 -*-msg = "中国"print msg#解码在编码的过程,encoding是申明用申明这段代码是什么编码gbk_str = msg.decode(encoding='utf-8').encode(encoding='gbk')print gbk_str#其实两种输出的结果是一样的
在Python2中默认是使用gbk来解释IDE中的代码的,所以无法直接在Python命令行中直接输入中文,所以我们才会使用 #-*-coding:utf-8 -*-来申明头部,我们到底需要使用什么语言来解释下面代码。细心的人肯定是发现了一个问题,申明头部只是使用utf-8来解释下面的话,按理说命令行中虽然不报错,但是应该也是乱码才是,这里为啥会直接输出中文呢毕竟DOS命令行中默认支持的是gbk格式的字符代码呀?这里就涉及到另外的一个概念了。Python到内存解释器里面,默认是用的Unicode,文件加载到内存后自动解码成Unicode,而Unicode是外国码,自然也就可以翻译来自utf-8的编码,也可以翻译成gbk的编码了。顾可以显示中文了。
PS:这里我们得出一个结论:python2 中解码动作是必须的,但是编码可以不用,因为内存就是Unicode
1.2、Python3中字符编码的问题:
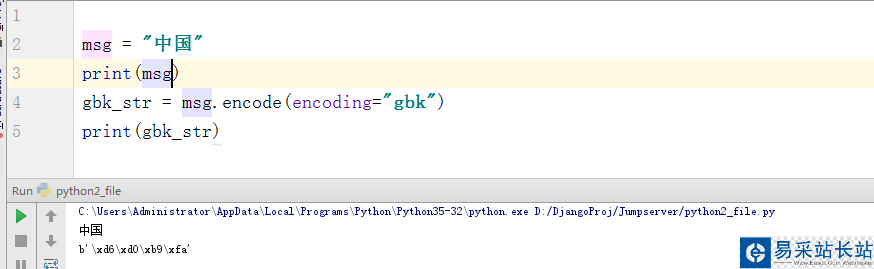
额,这还有什么可以说的呢?Python3默认就是使用utf-8解释代码的。也就是行首自带 #-*-coding:utf-8 -*-(GBM),所以也就不存在解码的问题。但是我在这里提上一嘴(其实就是怕自己以后也忘了,嘿嘿),如果我们将utf-8的字符编码的格式给编码成gbk。这里会输出bytes格式的东西。
新闻热点






疑难解答













