前言
最近工作中遇到一个需求,需要将京东上图书的图片下载下来,假如我们想把京东商城图书类的图片类商品图片全部下载到本地,通过手工复制粘贴将是一项非常庞大的工程,此时,可以用Python网络爬虫实现,这类爬虫称为图片爬虫,接下来,我们将实现该爬虫。
实现分析
首先,打开要爬取的第一个网页,这个网页将作为要爬取的起始页面。我们打开京东,选择图书分类,由于图书所有种类的图书有很多,我们选择爬取所有编程语言的图书图片吧,网址为:https://list.jd.com/list.html?cat=1713,3287,3797&page=1&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main
如图:
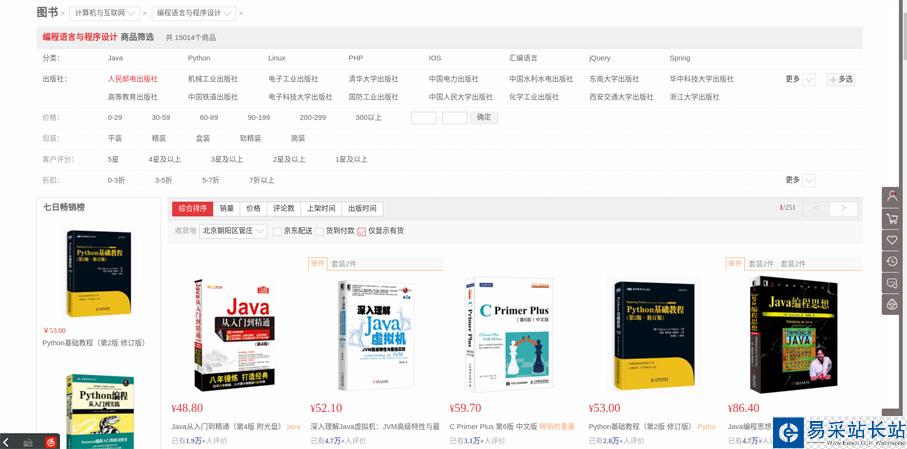
进去后,我们会发现总共有251页。
那么我们怎么才能自动爬取第一页以外的其他页面呢?
可以单击“下一页”,观察网址的变化。在单击了下一页之后,发现网址变成了https://list.jd.com/list.html?cat=1713,3287,3797&page=2&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main。
我们可以发现,在这里要获取第几页是通过URL网址识别的,即通过GET方式请求的。在这个GET请求中,有多个字段,其中有一个字段为page,对应值为2,由此,我们可以得到该网址中的关键信息为:https://list.jd.com/list.html?cat=1713,3287,3797&page=2。接下来,我们根据推测,将page=2改成page=6,发现我们能够成功进入第6页。
由此,我们可以想到自动获取多个页面的方法:可以使用for循环实现,每次循环后,对应的网址中page字段加1,即自动切换到下一页。
在每页中,我们都要提取对应的图片,可以使用正则表达式匹配源码中图片的链接部分,然后通过urllib.request.urlretrieve()将对应链接的图片保存到本地。
但是这里有一个问题,该网页中的图片不仅包括列表中的商品图片,还包括旁边的一些无关图片,所以我们可以先进行一次信息过滤,第一次信息过滤将中间的商品列表部分数据留下,将其他部分的数据过滤掉。可以单击右键,然后查看网页的源代码,如图:
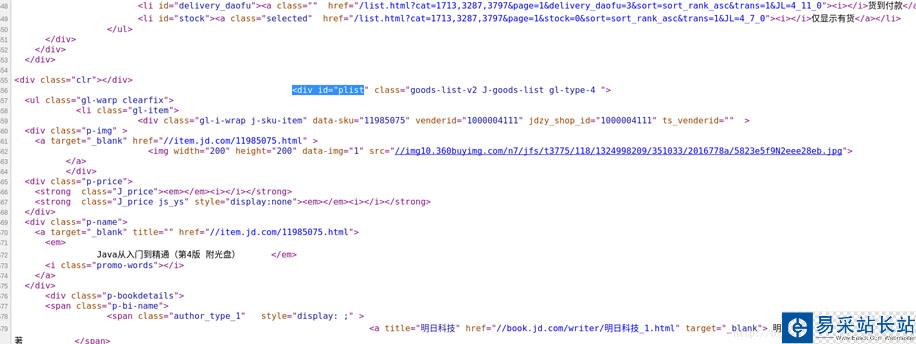
可以通过商品列表中的第一个商品名为“JAVA从入门到精通”快速定位到源码中的对应位置,然后观察其商品列表部分的特殊标识,可以看到,其上方有处“<div id="plist”代码,然后我们在源码中搜索该代码,发现只有一个地方有,随后打开其他页的对应页面,发现仍然具有这个规律,说明该特殊标识可以作为有效信息的起始过滤位置。当然,你可以使用其他的代码作为特殊标识,但是该特殊标识要满足唯一性,并且要包含要爬取的信息。
新闻热点






疑难解答













