决策树原理:从数据集中找出决定性的特征对数据集进行迭代划分,直到某个分支下的数据都属于同一类型,或者已经遍历了所有划分数据集的特征,停止决策树算法。
每次划分数据集的特征都有很多,那么我们怎么来选择到底根据哪一个特征划分数据集呢?这里我们需要引入信息增益和信息熵的概念。
一、信息增益
划分数据集的原则是:将无序的数据变的有序。在划分数据集之前之后信息发生的变化称为信息增益。知道如何计算信息增益,我们就可以计算根据每个特征划分数据集获得的信息增益,选择信息增益最高的特征就是最好的选择。首先我们先来明确一下信息的定义:符号xi的信息定义为 l(xi)=-log2 p(xi),p(xi)为选择该类的概率。那么信息源的熵H=-∑p(xi)·log2 p(xi)。根据这个公式我们下面编写代码计算香农熵
def calcShannonEnt(dataSet): NumEntries = len(dataSet) labelsCount = {} for i in dataSet: currentlabel = i[-1] if currentlabel not in labelsCount.keys(): labelsCount[currentlabel]=0 labelsCount[currentlabel]+=1 ShannonEnt = 0.0 for key in labelsCount: prob = labelsCount[key]/NumEntries ShannonEnt -= prob*log(prob,2) return ShannonEnt上面的自定义函数我们需要在之前导入log方法,from math import log。 我们可以先用一个简单的例子来测试一下
def createdataSet(): #dataSet = [['1','1','yes'],['1','0','no'],['0','1','no'],['0','0','no']] dataSet = [[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,0,'no']] labels = ['no surfacing','flippers'] return dataSet,labels

这里的熵为0.811,当我们增加数据的类别时,熵会增加。这里更改后的数据集的类别有三种‘yes'、‘no'、‘maybe',也就是说数据越混乱,熵就越大。
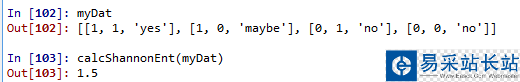
分类算法出了需要计算信息熵,还需要划分数据集。决策树算法中我们对根据每个特征划分的数据集计算一次熵,然后判断按照哪个特征划分是最好的划分方式。
def splitDataSet(dataSet,axis,value): retDataSet = [] for featVec in dataSet: if featVec[axis] == value: reducedfeatVec = featVec[:axis] reducedfeatVec.extend(featVec[axis+1:]) retDataSet.append(reducedfeatVec) return retDataSet
axis表示划分数据集的特征,value表示特征的返回值。这里需要注意extend方法和append方法的区别。举例来说明这个区别

下面我们测试一下划分数据集函数的结果:

axis=0,value=1,按myDat数据集的第0个特征向量是否等于1进行划分。
新闻热点






疑难解答













