这段时间看了数据分析方面的内容,对Python中的numpy和pandas有了最基础的了解。我知道如果我不用这些技能做些什么的话,很快我就会忘记。想起之前群里发过一个学校的四六级成绩表,正好可以用来熟悉一下pandas中的一些用法。
1.数据介绍。
成绩表中包含的字段十分详细,里面有年级、性别、姓名、分数等等的一系列内容,我只想简单的分析一下我们学校的四六级过关率而已,所以去除了一些不必要的字段。留下的有如下几个字段:
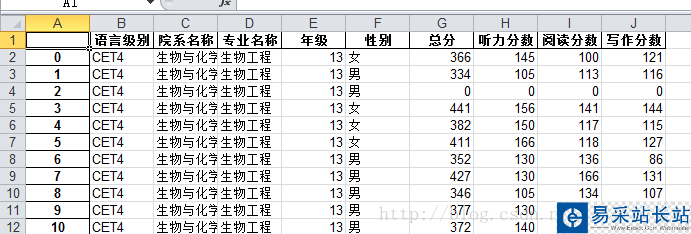
第一列是自增的序号,没有什么实际意义。
第二列就是代表着该学生参加的是四级还是六级。
第三列是我们学校的院系名称。
第四列是学校院系的各个专业。
第五列是年级,13代表着2013年入学。
第六列是性别。
后面的三列分别是总分、听力、阅读、写作等。
其中总分为0的都是缺考的。一共有接近9000条数据(没有报名的不在其中)。
2.预期结果。
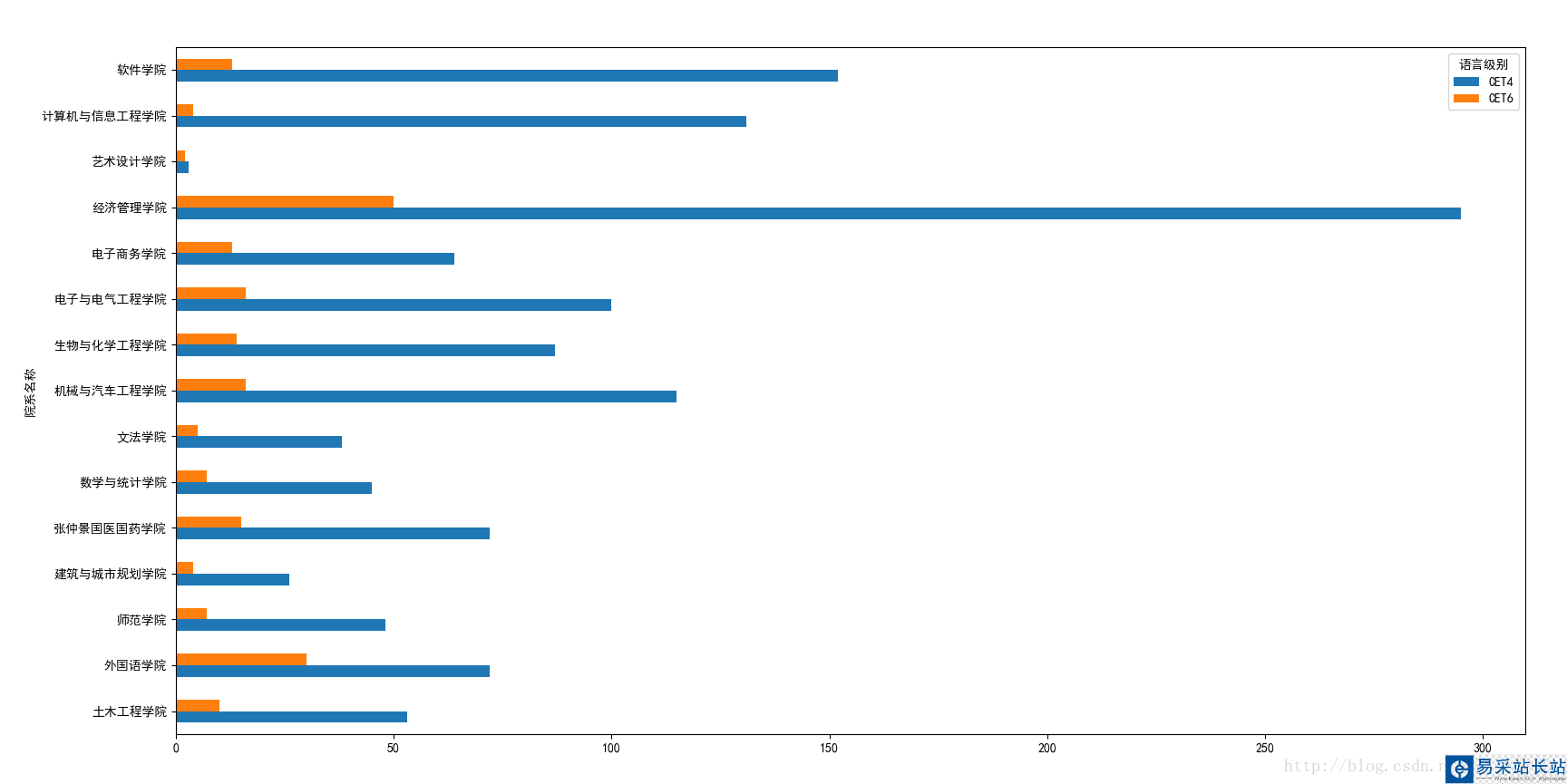
我想利用这些数据最终通过图标的形式展示出以下几点:
1.各个学院的四六级平均分。
2.各个学院的四六级过关人数。
3.各个学院的各个年级过关人数。
4.各个年级的过关人数。
5.男生女生分别过关人数。
最终结果:
各个学院的四六级过关人数:
3.实现过程。
(1)导入依赖包。
程序分别使用了pandas进行分组转换,和matplotlib提供的绘图功能。
import pandas as pdimport matplotlib.pylab as plt
(2)加载数据。
想要分析数据自然要得到数据了,我将整理的数据存放在sj.xls中,是一个Excel类型的数据。
这一步使用pandas的read_excel即可,生成一个DataFrame对象。
#加载全部数据sj = pd.read_excel(r'F:/DataAnalysis/sj.xls')
加载完之后输出一下看看内容:
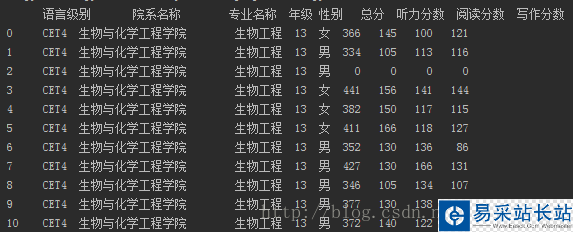
除了排版没有对齐之外其他都一样。
(3)统计各个学院平均分。
在这里就可以完成我们预期的第一个结果:
各个学院的四六级平均分:
想要各个学院的情况当然是要根据学院来进行分组了,同时也需要分出“CET4”和“CET6”两组。使用groupby即可,这样会生成一个SeriesGroupBy对象,然后再调用mean函数(默认是轴0计算,也就是我们想要的结果)即可统计出平均分情况。
#按照各个学院进行分组xymean = sj['总分'].groupby([sj['院系名称'],sj['语言级别']])#计算各个学院的平均分数xymean = xymean.mean()
新闻热点






疑难解答













