本篇主要介绍:常见的字典方法、如何处理查不到的键、标准库中 dict 类型的变种、散列表的工作原理等。一下是全部内容:
泛映射类型
collections.abc 模块中有 Mapping 和 MutableMapping 这两个抽象基类,它们的作用是为 dict 和其他类似的类型定义形式接口。
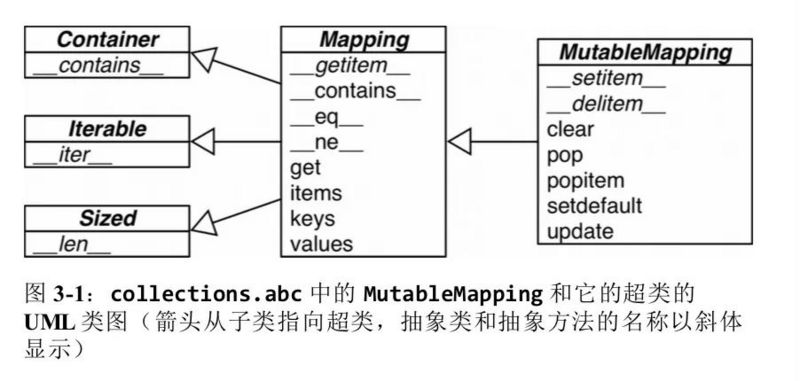
标准库里所有映射类型都是利用 dict 来实现的,它们有个共同的限制,即只有可散列的数据类型才能用做这些映射里的键。
问题: 什么是可散列的数据类型?
在 python 词汇表(https://docs.python.org/3/glossary.html#term-hashable)中,关于可散列类型的定义是这样的:
如果一个对象是可散列的,那么在这个对象的生命周期中,它的散列值是不变的,而且这个对象需要实现 __hash__() 方法。另外可散列对象还要有 __eq__() 方法,这样才能跟其他键做比较。如果两个可散列对象是相等的,那么它们的散列只一定是一样的
根据这个定义,原子不可变类型(str,bytes和数值类型)都是可散列类型,frozenset 也是可散列的(因为根据其定义,frozenset 里只能容纳可散列类型),如果元组内都是可散列类型的话,元组也是可散列的(元组虽然是不可变类型,但如果它里面的元素是可变类型,这种元组也不能被认为是不可变的)。
一般来讲,用户自定义的类型的对象都是可散列的,散列值就是它们的 id() 函数的返回值,所以这些对象在比较的时候都是不相等的。(如果一个对象实现了 eq 方法,并且在方法中用到了这个对象的内部状态的话,那么只有当所有这些内部状态都是不可变的情况下,这个对象才是可散列的。)
根据这些定义,字典提供了很多种构造方法,https://docs.python.org/3/library/stdtypes.html#mapping-types-dict 这个页面有个例子来说明创建字典的不同方式。
>>> a = dict(one=1, two=2, three=3)>>> b = {'one': 1, 'two': 2, 'three': 3}>>> c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))>>> d = dict([('two', 2), ('one', 1), ('three', 3)])>>> e = dict({'three': 3, 'one': 1, 'two': 2})>>> a == b == c == d == eTrue除了这些方法以外,还可以用字典推导的方式来建造新 dict。
字典推导
自 Python2.7 以来,列表推导和生成器表达式的概念就移植到了字典上,从而有了字典推导。字典推导(dictcomp)可以从任何以键值对作为元素的可迭代对象中构建出字典。
比如:
>>> data = [(1, 'a'), (2, 'b'), (3, 'c')]>>> data_dict = {num: letter for num, letter in data}>>> data_dict{1: 'a', 2: 'b', 3: 'c'}
新闻热点






疑难解答













