决策树分类与上一篇博客k近邻分类的最大的区别就在于,k近邻是没有训练过程的,而决策树是通过对训练数据进行分析,从而构造决策树,通过决策树来对测试数据进行分类,同样是属于监督学习的范畴。决策树的结果类似如下图:
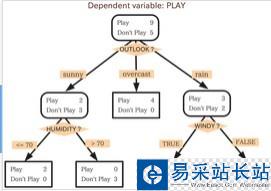
图中方形方框代表叶节点,带圆边的方框代表决策节点,决策节点与叶节点的不同之处就是决策节点还需要通过判断该节点的状态来进一步分类。
那么如何通过训练数据来得到这样的决策树呢?
这里涉及要信息论中一个很重要的信息度量方式,香农熵。通过香农熵可以计算信息增益。
香农熵的计算公式如下:
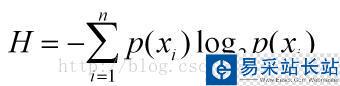
p(xi)代表数据被分在i类的概率,可以通过计算数据集中i类的个数与总的数据个数之比得到,计算香农熵的python代码如下:
from math import log def calcShannonEnt(dataSet): numEntries=len(dataSet) labelCounts={} for featVec in dataSet: currentLabel=featVec[-1] if currentLabel not in labelCounts.keys(): labelCounts[currentLabel]=0 labelCounts[currentLabel]+=1 shannonEnt=0.0 for key in labelCounts: prob=float(labelCounts[key])/numEntries shannonEnt-=prob*log(prob,2) return shannonEnt 一般来说,数据集中,不同的类别越多,即信息量越大,那么熵值越大,通过计算熵,就可以知道选择哪一个特征能够最好的分开数据,这个特征就是一个决策节点。
下面就可以根据训练数据开始构造决策树。
首先编写一个根据给定特征划分数据集的函数:
#划分数据集,返回第axis轴为value值的数据集 def splitDataSet(dataset,axis,value): retDataSet=[] for featVec in dataset: if featVec[axis]==value: reducedFeatVec=featVec[:] del(reducedFeatVec[axis]) retDataSet.append(reducedFeatVec) return retDataSet
下面找出数据集中能够最好划分数据的那个特征,它的原理是计算经过每一个特征轴划分后的数据的信息增益,信息增益越大,代表通过该特征轴划分是最优的。
#选择最好的数据集划分方式,返回最佳的轴 def chooseBestFeatureToSplit(dataset): numFeatures=len(dataset[0])-1 baseEntrypy=calcShannonEnt(dataset) bestInfoGain=0.0 bestFeature=-1 for i in range(numFeatures): featList=[example[i] for example in dataset] uniqueVals=set(featList) newEntrypy=0.0 for value in uniqueVals: subDataSet=splitDataSet(dataset,i,value) prob=len(subDataSet)/float(len(dataset)) newEntrypy+=prob*calcShannonEnt(subDataSet) infoGain=baseEntrypy-newEntrypy #计算信息增益,信息增益最大,就是最好的划分 if infoGain>bestInfoGain: bestInfoGain=infoGain bestFeature=i return bestFeature
新闻热点






疑难解答













