本文为大家分享了决策树之C4.5算法,供大家参考,具体内容如下
1. C4.5算法简介
C4.5算法是用于生成决策树的一种经典算法,是ID3算法的一种延伸和优化。C4.5算法对ID3算法主要做了一下几点改进:
(1)通过信息增益率选择分裂属性,克服了ID3算法中通过信息增益倾向于选择拥有多个属性值的属性作为分裂属性的不足;
(2)能够处理离散型和连续型的属性类型,即将连续型的属性进行离散化处理;
(3)构造决策树之后进行剪枝操作;
(4)能够处理具有缺失属性值的训练数据。
2. 分裂属性的选择——信息增益率
分裂属性选择的评判标准是决策树算法之间的根本区别。区别于ID3算法通过信息增益选择分裂属性,C4.5算法通过信息增益率选择分裂属性。
属性A的“分裂信息”(split information):
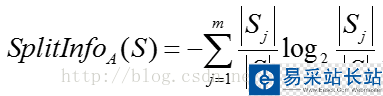
其中,训练数据集S通过属性A的属性值划分为m个子数据集,
通过属性A分裂之后样本集的信息增益:
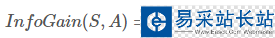
信息增益的详细计算方法,可以参考博客“决策树之ID3算法及其Python实现”中信息增益的计算。
通过属性A分裂之后样本集的信息增益率:
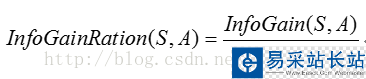
通过C4.5算法构造决策树时,信息增益率最大的属性即为当前节点的分裂属性,随着递归计算,被计算的属性的信息增益率会变得越来越小,到后期则选择相对比较大的信息增益率的属性作为分裂属性。
3. 连续型属性的离散化处理
当属性类型为离散型,无须对数据进行离散化处理;当属性类型为连续型,则需要对数据进行离散化处理。C4.5算法针对连续属性的离散化处理,核心思想:将属性A的N个属性值按照升序排列;通过二分法将属性A的所有属性值分成两部分(共有N-1种划分方法,二分的阈值为相邻两个属性值的中间值);计算每种划分方法对应的信息增益,选取信息增益最大的划分方法的阈值作为属性A二分的阈值。详细流程如下:
(1)将节点Node上的所有数据样本按照连续型属性A的具体取值,由小到大进行排列,得到属性A的属性值取值序列
新闻热点






疑难解答













