决策树通常在机器学习中用于分类。
优点:计算复杂度不高,输出结果易于理解,对中间值缺失不敏感,可以处理不相关特征数据。
缺点:可能会产生过度匹配问题。
适用数据类型:数值型和标称型。
1.信息增益
划分数据集的目的是:将无序的数据变得更加有序。组织杂乱无章数据的一种方法就是使用信息论度量信息。通常采用信息增益,信息增益是指数据划分前后信息熵的减少值。信息越无序信息熵越大,获得信息增益最高的特征就是最好的选择。
熵定义为信息的期望,符号xi的信息定义为:

其中p(xi)为该分类的概率。
熵,即信息的期望值为:
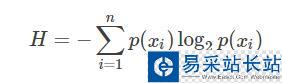
计算信息熵的代码如下:
def calcShannonEnt(dataSet): numEntries = len(dataSet) labelCounts = {} for featVec in dataSet: currentLabel = featVec[-1] if currentLabel not in labelCounts: labelCounts[currentLabel] = 0 labelCounts[currentLabel] += 1 shannonEnt = 0 for key in labelCounts: shannonEnt = shannonEnt - (labelCounts[key]/numEntries)*math.log2(labelCounts[key]/numEntries) return shannonEnt可以根据信息熵,按照获取最大信息增益的方法划分数据集。
2.划分数据集
划分数据集就是将所有符合要求的元素抽出来。
def splitDataSet(dataSet,axis,value): retDataset = [] for featVec in dataSet: if featVec[axis] == value: newVec = featVec[:axis] newVec.extend(featVec[axis+1:]) retDataset.append(newVec) return retDataset
3.选择最好的数据集划分方式
信息增益是熵的减少或者是信息无序度的减少。
def chooseBestFeatureToSplit(dataSet): numFeatures = len(dataSet[0]) - 1 bestInfoGain = 0 bestFeature = -1 baseEntropy = calcShannonEnt(dataSet) for i in range(numFeatures): allValue = [example[i] for example in dataSet]#列表推倒,创建新的列表 allValue = set(allValue)#最快得到列表中唯一元素值的方法 newEntropy = 0 for value in allValue: splitset = splitDataSet(dataSet,i,value) newEntropy = newEntropy + len(splitset)/len(dataSet)*calcShannonEnt(splitset) infoGain = baseEntropy - newEntropy if infoGain > bestInfoGain: bestInfoGain = infoGain bestFeature = i return bestFeature
4.递归创建决策树
结束条件为:程序遍历完所有划分数据集的属性,或每个分支下的所有实例都具有相同的分类。
当数据集已经处理了所有属性,但是类标签还不唯一时,采用多数表决的方式决定叶子节点的类型。
新闻热点






疑难解答













