从这一章开始进入正式的算法学习。
首先我们学习经典而有效的分类算法:决策树分类算法。
1、决策树算法
决策树用树形结构对样本的属性进行分类,是最直观的分类算法,而且也可以用于回归。不过对于一些特殊的逻辑分类会有困难。典型的如异或(XOR)逻辑,决策树并不擅长解决此类问题。
决策树的构建不是唯一的,遗憾的是最优决策树的构建属于NP问题。因此如何构建一棵好的决策树是研究的重点。
J. Ross Quinlan在1975提出将信息熵的概念引入决策树的构建,这就是鼎鼎大名的ID3算法。后续的C4.5, C5.0, CART等都是该方法的改进。
熵就是“无序,混乱”的程度。刚接触这个概念可能会有些迷惑。想快速了解如何用信息熵增益划分属性,可以参考这位兄弟的文章:Python机器学习之决策树算法
如果还不理解,请看下面这个例子。
假设要构建这么一个自动选好苹果的决策树,简单起见,我只让他学习下面这4个样本:
样本 红 大 好苹果
0 1 1 1
1 1 0 1
2 0 1 0
3 0 0 0
样本中有2个属性,A0表示是否红苹果。A1表示是否大苹果。
那么这个样本在分类前的信息熵就是S = -(1/2 * log(1/2) + 1/2 * log(1/2)) = 1。
信息熵为1表示当前处于最混乱,最无序的状态。
本例仅2个属性。那么很自然一共就只可能有2棵决策树,如下图所示:
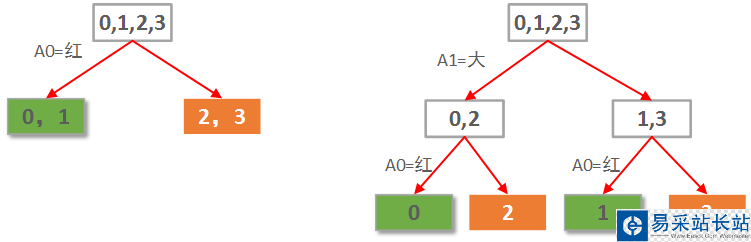
显然左边先使用A0(红色)做划分依据的决策树要优于右边用A1(大小)做划分依据的决策树。
当然这是直觉的认知。定量的考察,则需要计算每种划分情况的信息熵增益。
先选A0作划分,各子节点信息熵计算如下:
0,1叶子节点有2个正例,0个负例。信息熵为:e1 = -(2/2 * log(2/2) + 0/2 * log(0/2)) = 0。
2,3叶子节点有0个正例,2个负例。信息熵为:e2 = -(0/2 * log(0/2) + 2/2 * log(2/2)) = 0。
因此选择A0划分后的信息熵为每个子节点的信息熵所占比重的加权和:E = e1*2/4 + e2*2/4 = 0。
选择A0做划分的信息熵增益G(S, A0)=S - E = 1 - 0 = 1.
新闻热点






疑难解答













