SVM(support vector machine)支持向量机:
注意:本文不准备提到数学证明的过程,一是因为有一篇非常好的文章解释的非常好:支持向量机通俗导论(理解SVM的三层境界) ,另一方面是因为我只是个程序员,不是搞数学的(主要是因为数学不好。),主要目的是将SVM以最通俗易懂,简单粗暴的方式解释清楚。
线性分类:
先从线性可分的数据讲起,如果需要分类的数据都是线性可分的,那么只需要一根直线f(x)=wx+b就可以分开了,类似这样:
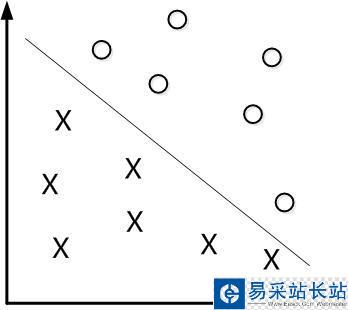
这种方法被称为:线性分类器,一个线性分类器的学习目标便是要在n维的数据空间中找到一个超平面(hyper plane)。也就是说,数据不总是二维的,比如,三维的超平面是面。但是有个问题:
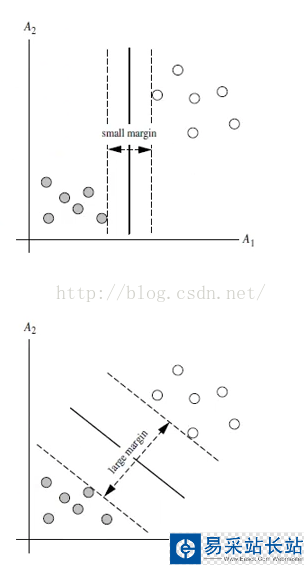
上述两种超平面,都可以将数据进行分类,由此可推出,其实能有无数个超平面能将数据划分,但是哪条最优呢?
最大间隔分类器Maximum Margin Classifier:
简称MMH, 对一个数据点进行分类,当超平面离数据点的“间隔”越大,分类的确信度(confidence)也越大。所以,为了使得分类的确信度尽量高,需要让所选择的超平面能够最大化这个“间隔”值。这个间隔就是下图中的Gap的一半。
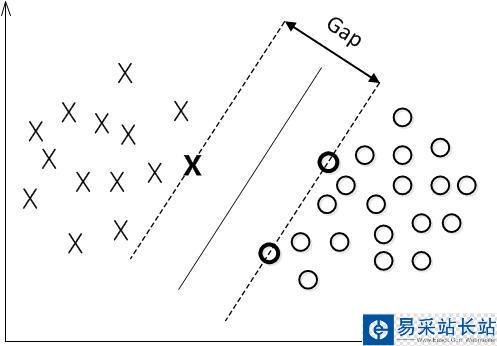
用以生成支持向量的点,如上图XO,被称为支持向量点,因此SVM有一个优点,就是即使有大量的数据,但是支持向量点是固定的,因此即使再次训练大量数据,这个超平面也可能不会变化。
非线性分类:
数据大多数情况都不可能是线性的,那如何分割非线性数据呢?
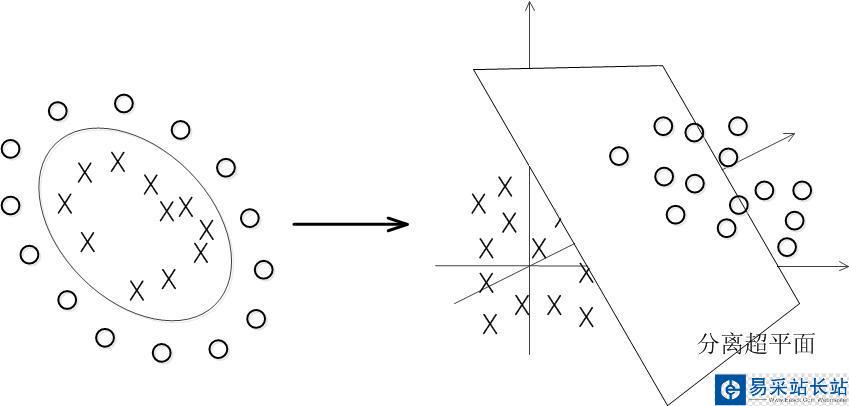
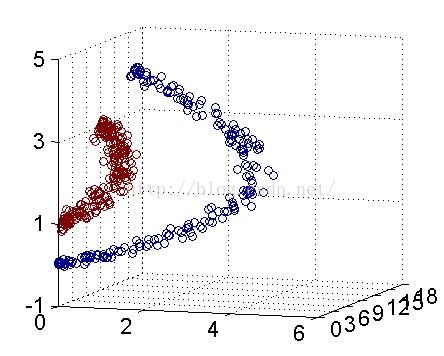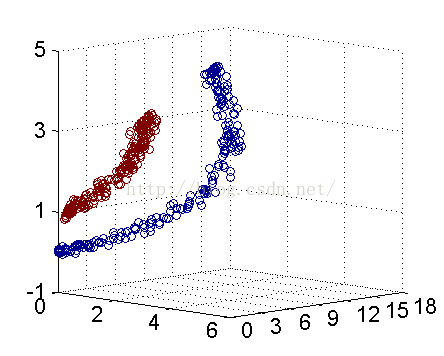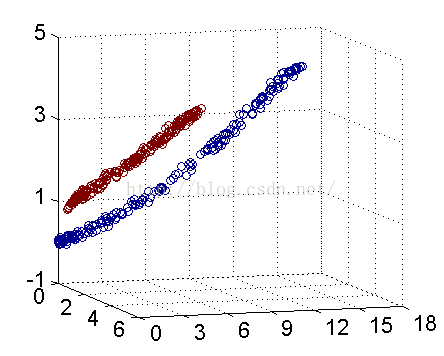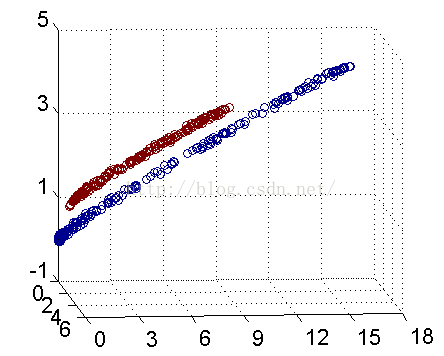
解决方法是将数据放到高维度上再进行分割,如下图:
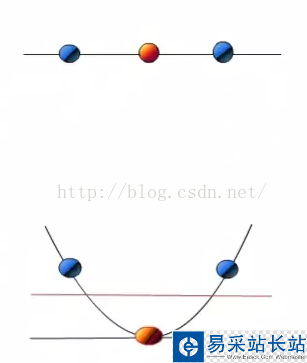
当f(x)=x时,这组数据是个直线,如上半部分,但是当我把这组数据变为f(x)=x^2时,这组数据就变成了下半部分的样子,也就可以被红线所分割。
比如说,我这里有一组三维的数据X=(x1,x2,x3),线性不可分割,因此我需要将他转换到六维空间去。因此我们可以假设六个维度分别是:x1,x2,x3,x1^2,x1*x2,x1*x3,当然还能继续展开,但是六维的话这样就足够了。
新的决策超平面:d(Z)=WZ+b,解出W和b后带入方程,因此这组数据的超平面应该是:d(Z)=w1x1+w2x2+w3x3+w4*x1^2+w5x1x2+w6x1x3+b但是又有个新问题,转换高纬度一般是以内积(dot product)的方式进行的,但是内积的算法复杂度非常大。
新闻热点






疑难解答













