爬取的站点:http://beijing.8684.cn/
(1)环境配置,直接上代码:
# -*- coding: utf-8 -*-import requests ##导入requestsfrom bs4 import BeautifulSoup ##导入bs4中的BeautifulSoupimport osheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}all_url = 'http://beijing.8684.cn' ##开始的URL地址start_html = requests.get(all_url, headers=headers) #print (start_html.text)Soup = BeautifulSoup(start_html.text, 'lxml') # 以lxml的方式解析html文档(2)爬取站点分析
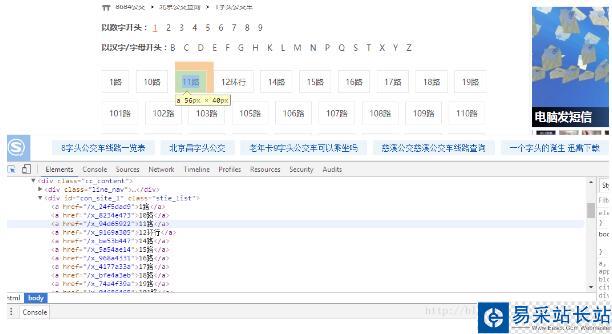
1、北京市公交线路分类方式有3种:

本文通过数字开头来进行爬取,“F12”启动开发者工具,点击“Elements”,点击“1”,可以发现链接保存在<div class="bus_kt_r1">里面,故只需要提取出div里的href即可:
代码:
all_a = Soup.find(‘div',class_='bus_kt_r1').find_all(‘a')
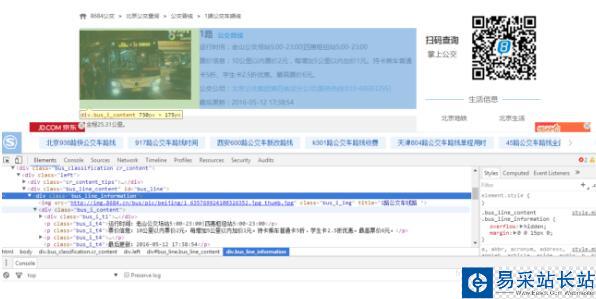
2、接着往下,发现每1路的链接都在<div id="con_site_1" class="site_list"> 的<a>里面,取出里面的herf即为线路网址,其内容即为线路名称,代码:
href = a['href'] #取出a标签的href 属性html = all_url + hrefsecond_html = requests.get(html,headers=headers)#print (second_html.text)Soup2 = BeautifulSoup(second_html.text, 'lxml') all_a2 = Soup2.find('div',class_='cc_content').find_all('div')[-1].find_all('a') # 既有id又有class的div不知道为啥取不出来,只好迂回取了3、打开线路链接,就可以看到具体的站点信息了,打开页面分析文档结构后发现:线路的基本信息存放在<div class="bus_i_content">里面,而公交站点信息则存放在<div class="bus_line_top">及<div class="bus_line_site">里面,提取代码:
title1 = a2.get_text() #取出a1标签的文本href1 = a2['href'] #取出a标签的href 属性#print (title1,href1)html_bus = all_url + href1 # 构建线路站点urlthrid_html = requests.get(html_bus,headers=headers)Soup3 = BeautifulSoup(thrid_html.text, 'lxml') bus_name = Soup3.find('div',class_='bus_i_t1').find('h1').get_text() # 提取线路名bus_type = Soup3.find('div',class_='bus_i_t1').find('a').get_text() # 提取线路属性bus_time = Soup3.find_all('p',class_='bus_i_t4')[0].get_text() # 运行时间bus_cost = Soup3.find_all('p',class_='bus_i_t4')[1].get_text() # 票价bus_company = Soup3.find_all('p',class_='bus_i_t4')[2].find('a').get_text() # 公交公司bus_update = Soup3.find_all('p',class_='bus_i_t4')[3].get_text() # 更新时间bus_label = Soup3.find('div',class_='bus_label')if bus_label: bus_length = bus_label.get_text() # 线路里程else: bus_length = []#print (bus_name,bus_type,bus_time,bus_cost,bus_company,bus_update)all_line = Soup3.find_all('div',class_='bus_line_top') # 线路简介all_site = Soup3.find_all('div',class_='bus_line_site')# 公交站点line_x = all_line[0].find('div',class_='bus_line_txt').get_text()[:-9]+all_line[0].find_all('span')[-1].get_text()sites_x = all_site[0].find_all('a')sites_x_list = [] # 上行线路站点for site_x in sites_x: sites_x_list.append(site_x.get_text())line_num = len(all_line)if line_num==2: # 如果存在环线,也返回两个list,只是其中一个为空 line_y = all_line[1].find('div',class_='bus_line_txt').get_text()[:-9]+all_line[1].find_all('span')[-1].get_text() sites_y = all_site[1].find_all('a') sites_y_list = [] # 下行线路站点 for site_y in sites_y: sites_y_list.append(site_y.get_text())else: line_y,sites_y_list=[],[]information = [bus_name,bus_type,bus_time,bus_cost,bus_company,bus_update,bus_length,line_x,sites_x_list,line_y,sites_y_list]
新闻热点






疑难解答













