课程体系结构:
1、Requests框架:自动爬取HTML页面与自动网络请求提交
2、robots.txt:网络爬虫排除标准
3、BeautifulSoup框架:解析HTML页面
4、Re框架:正则框架,提取页面关键信息
5、Scrapy框架:网络爬虫原理介绍,专业爬虫框架介绍
理念:The Website is the API ...
Python语言常用的IDE工具
文本工具类IDE:
IDLE、Notepad++、Sublime Text、Vim & Emacs、Atom、Komodo Edit
集成工具IDE:
PyCharm、Wing、PyDev & Eclipse、Visual Studio、Anaconda & Spyder、Canopy
·IDLE是Python自带的默认的常用的入门级编写工具,它包含交互式文件式两种方式。适用于较短的程序。
·Sublime Text是专为程序员开发的第三方专用编程工具,可以提高编程体验,具有多种编程风格。
·Wing是Wingware公司提供的收费IDE,调试功能丰富,具有版本控制,版本同步功能,适合于多人共同开发。适用于编写大型程序。
·Visual Studio是微软公司维护的,可以通过配置PTVS编写Python,主要以Windows环境为主,调试功能丰富。
·Eclipse是一款开源的IDE开发工具,可以通过配置PyDev来编写Python,但是配置过程复杂,需要有一定的开发经验。
·PyCharm分为社区版和专业版,社区版免费,具有简单、集成度高的特点,适用于编写较复杂的工程。
适用于科学计算、数据分析的IDE:
·Canopy是由Enthought公司维护的收费工具,支持近500个第三方库,适合科学计算领域应用开发。
·Anaconda是开源免费的,支持近800个第三方库。
Requests库入门
Requests的安装:
Requests库是目前公认的爬取网页最好的Python第三方库,具有简单、简捷的特点。
官方网站:http://www.python-requests.org
在"C:/Windows/System32"中找到"cmd.exe",使用管理员身份运行,在命令行中输入:“pip install requests”运行。
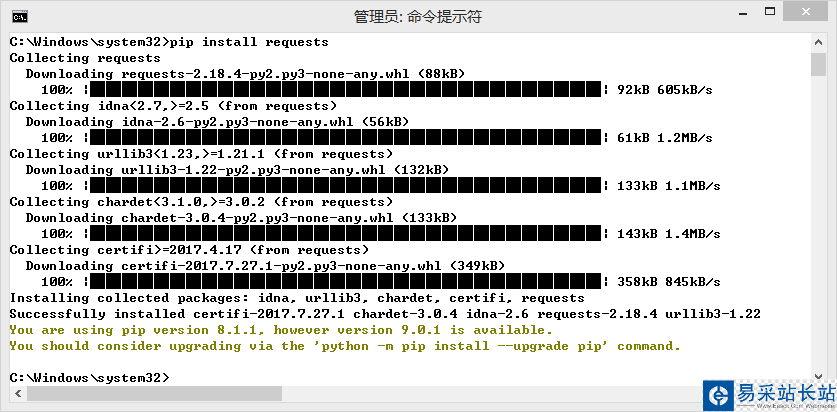
使用IDLE测试Requests库:
>>> import requests>>> r = requests.get("http://www.baidu.com")#抓取百度页面>>> r.status_code>>> r.encoding = 'utf-8'>>> r.textRequests库的7个主要方法
| 方法 | 说明 |
| requests.request() | 构造一个请求,支撑以下各方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete() | 向HTML页面提交删除请求,对应于HTTP的DELET |
新闻热点






疑难解答













